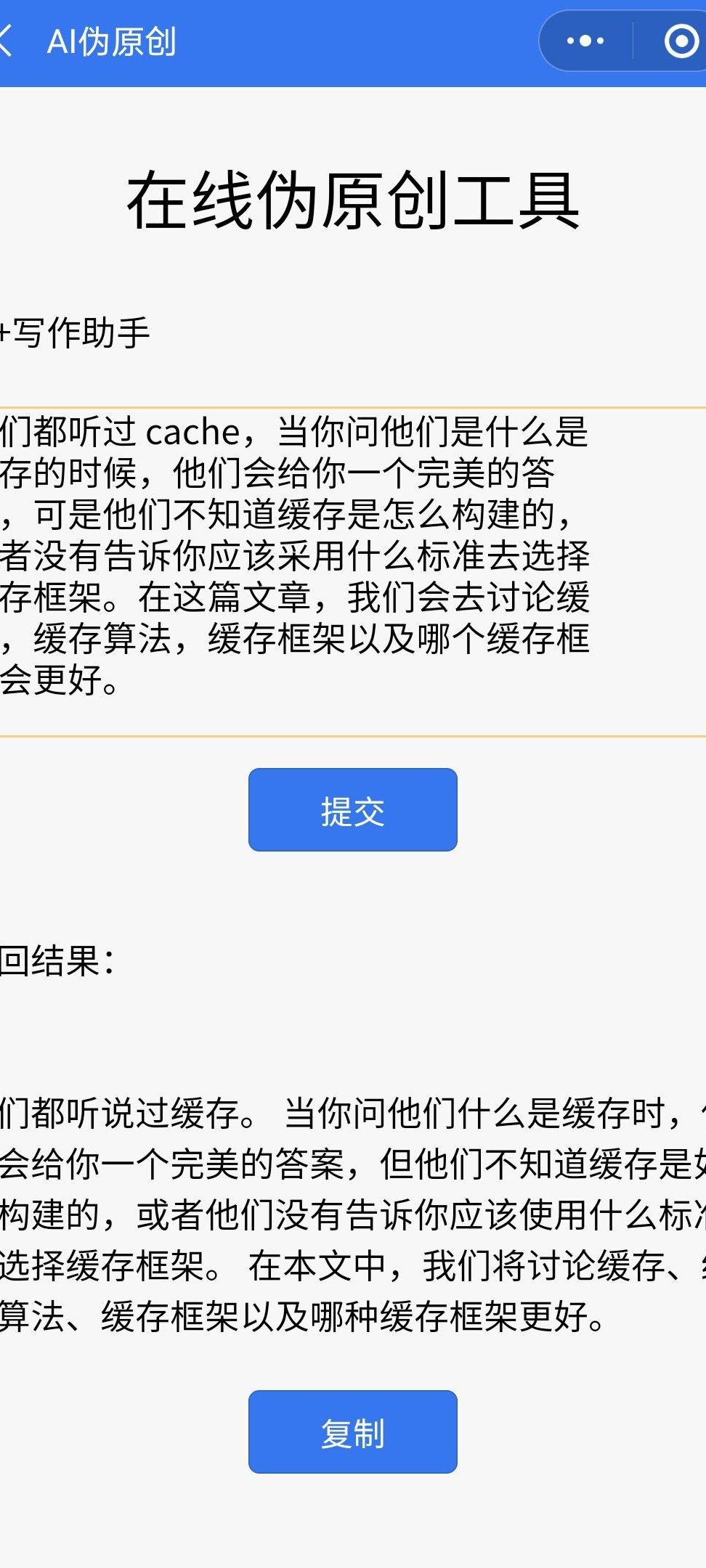
📌 AI 深度伪原创:披着 “创新” 外衣的文字游戏?
现在打开任何一个内容平台,你都可能刷到这样的文章 —— 读起来通顺流畅,观点看似新颖,但仔细琢磨就会发现,核心论据和框架都似曾相识。这背后很可能藏着 AI 深度伪原创的影子。和早期那种简单替换同义词的 “伪原创” 不同,现在的 AI 工具能做到句式重组、逻辑微调甚至案例替换,让一篇文章看起来和原文 “神似形不似”。
这种技术到底有多厉害?去年某科技博客做过测试,用一款主流 AI 伪原创工具处理一篇 1500 字的科技评论,输出的内容在查重软件上的重复率只有 8%,但明眼人能看出,文章的核心论点、数据引用甚至几个关键比喻都和原文高度重合。更夸张的是,有些工具能根据原文风格生成 “衍生内容”,比如把一篇学术论文改写成通俗科普文,结构完全打乱,但核心信息一个没少。
但这里有个绕不开的问题:这种 “深度改写” 到底算不算原创? 有位做自媒体的朋友跟我吐槽,他花了三天采访写的行业分析,被人用 AI 改头换面后发到另一个平台,阅读量比他还高。对方还理直气壮:“文字都是重新生成的,不算抄。” 这种情况现在越来越多,已经成了内容行业的新痛点。
🔍 技术边界在哪里?从 “替换” 到 “再造” 的灰色地带
要搞清楚这个问题,得先看看 AI 深度伪原创的技术逻辑。现在主流的工具基本都基于大语言模型,比如 GPT-4、Claude 这些。它们不是简单的 “同义词库”,而是通过分析原文的语义结构,用自己的 “语言习惯” 重新表达。打个比方,原文说 “秋天的枫叶染红了山坡”,AI 可能会写成 “深秋时节,漫山的枫叶像被泼了颜料,红得晃眼”。
这种技术进步带来了新的模糊性。早期伪原创工具很容易被识破,因为改写后的句子常常不通顺,逻辑断层。但现在的 AI 能做到 “既保留信息又改变形式”,甚至能给文章加入新的案例或数据 —— 当然,这些新增内容很多也是从训练数据里 “借鉴” 来的。
有个细节特别值得注意:AI 的训练数据本身就可能包含大量未授权的原创内容。很多大模型的训练库爬取了全网文章,其中不乏受版权保护的作品。当 AI 基于这些数据生成 “伪原创” 时,本质上是在对别人的创作成果进行二次加工。这就好比一个人背了一万篇文章,然后用自己的话把里面的观点重新说一遍,你能说这完全是他的原创吗?
更棘手的是检测技术的滞后。现在主流的查重工具,比如知网、Turnitin,对这种深度伪原创的识别率还不到 30%。某高校的老师告诉我,他们发现有学生用 AI 改写论文,查重率合格,但内容内核和一篇已发表的论文高度一致,最后只能靠人工审核发现。这种技术代差,让很多平台和机构陷入被动。
⚖️ 道德天平:当 “效率” 撞上 “公平”
内容创作行业最近在吵一个话题:AI 伪原创是不是在 “窃取劳动成果”?去年有个案例挺典型,某知名财经作家的专栏文章被一家自媒体用 AI 改写后,标题和段落结构全变了,但核心的数据分析和预测结论几乎一致。读者看了改写后的文章,很难意识到原创作者的存在。
这就涉及到 “隐性抄袭” 的道德争议。传统抄袭一眼就能看出来,而 AI 伪原创像一层滤镜,把抄袭的痕迹模糊了。原创作者花几个月调研写出的深度报道,别人用 AI 花十分钟改改就能拿去盈利,这显然对创作者不公平。长此以往,谁还愿意沉下心来做原创?
更麻烦的是对信息真实性的影响。AI 在改写时可能会 “脑补” 信息。比如原文说 “某公司第三季度利润增长 10%”,AI 可能会写成 “该公司全年利润预计增长 15%”。这种微小的改动如果没被发现,很容易误导读者。去年就有健康类自媒体用 AI 改写医学文章,把 “可能有效” 改成 “肯定有效”,导致读者误用偏方出事。
平台的态度也很耐人寻味。有些内容平台为了追求更新速度和数量,对 AI 伪原创睁一只眼闭一只眼,甚至暗中鼓励 —— 毕竟机器产出的内容成本低、速度快。但这其实是饮鸩止渴,当平台上充斥着 “似是而非” 的内容,用户最终会失去信任。某资讯 APP 去年因为 AI 伪原创内容太多,用户留存率下降了 27%,这就是活生生的教训。
📜 法律和规则:滞后于技术的现实困境
目前关于 AI 伪原创的法律界定还很模糊。现行的著作权法主要针对 “复制行为”,但 AI 改写后的内容算不算 “复制”?这在司法实践中还没有统一标准。去年北京某法院审理的一起 AI 伪原创侵权案,原告是位科普作者,被告用 AI 改写了他的文章并商用。法院最终判被告侵权,但赔偿金额只有原创文章稿费的三分之一,理由是 “AI 改写带来了一定的创造性劳动”。
这种判决结果让很多原创作者感到无奈。一位律师朋友跟我说,现在这类案子的难点在于 “独创性” 的认定。AI 改写的内容到底有没有达到 “独创性” 的标准?如果只是改变了表达方式但保留核心思想,算不算侵权?这些问题在法律上还没有明确答案。
平台规则也参差不齐。微信公众号、知乎等平台对 AI 内容的审核越来越严,但很多中小平台为了流量,对 AI 伪原创采取 “默许” 态度。甚至有平台推出 “AI 伪原创工具”,专门帮用户 “洗稿” 赚钱。这种乱象的根源,在于缺乏统一的行业标准。
国际上的做法也值得参考。欧盟的《人工智能法案》要求 AI 生成的内容必须标明来源,美国版权局则规定,纯 AI 生成的内容不能获得版权保护,但 “人类参与创作的 AI 内容” 可以。这些尝试虽然还不完善,但至少指明了一个方向:明确 AI 在创作中的角色和责任。
💡 破局之路:技术向善需要 “双向约束”
要平衡 AI 伪原创的技术发展和道德边界,光靠骂或者禁肯定不行。得从技术和规则两方面下手。
技术层面,现在已经有团队在开发 “AI 创作溯源技术”。比如通过分析文本的 “语言指纹”,识别出内容是否由 AI 生成,甚至能追溯到原始参考资料。某大学的 NLP 实验室去年推出的溯源工具,对主流 AI 模型生成内容的识别率达到了 91%,这可能会成为未来的重要监管手段。
规则层面,行业需要建立 “AI 内容标签制度”。就像食品包装上要标明成分一样,AI 参与创作的内容也应该明确标注,让读者知道内容的生成方式。 Medium 平台已经开始试点这种做法,要求作者注明是否使用 AI 工具,以及使用的程度。这种透明化能减少误导,也能让原创作者的劳动得到认可。
对创作者来说,也得调整心态。AI 伪原创虽然能快速产出内容,但缺乏真正的思想和情感。读者最终认可的,还是那些有独特观点、有深度思考的内容。与其花心思 “洗稿”,不如把 AI 当成辅助工具,比如用它整理资料、优化语言,但核心观点和创作框架必须自己把控。
最后想说的是,技术本身没有对错,关键看怎么用。AI 伪原创如果用在辅助创作、提高效率上,可能是好事;但如果用来投机取巧、窃取别人的劳动成果,那就越过了红线。内容行业的生命力在于 “原创性”,不管技术怎么发展,这个核心不能丢。
【该文章由diwuai.com第五 ai 创作,第五 AI - 高质量公众号、头条号等自媒体文章创作平台 | 降 AI 味 + AI 检测 + 全网热搜爆文库
🔗立即免费注册 开始体验工具箱 - 朱雀 AI 味降低到 0%- 降 AI 去 AI 味】
🔗立即免费注册 开始体验工具箱 - 朱雀 AI 味降低到 0%- 降 AI 去 AI 味】















