最近几年,文生图模型火得一塌糊涂。从 DALL・E 2 到 Midjourney,再到 Stable Diffusion,这些工具让普通人也能输入一句文字,就得到一张像样的图片。你可能会好奇,这些 AI 到底是怎么 “听懂” 我们说的话,还能把文字变成实实在在的图像?这背后可不是简单的魔术,而是一整套复杂的技术逻辑。今天就来扒一扒文生图模型的底层原理,看看 AI 是如何完成从文字到图像的 “翻译” 的。
📝 文生图模型的核心:不是 “画” 而是 “猜”
很多人觉得文生图模型是像画家一样 “创作” 图像,其实不对。它的核心逻辑是 “猜测”—— 根据文字描述,从海量数据中学习到的规律里,一步步 “猜” 出最符合描述的图像。
这种 “猜” 不是随机的,而是基于概率。就像我们人类看到 “蓝天白云” 会联想到蓝色的天空和白色的云朵,AI 也是通过学习大量 “蓝天白云” 对应的图片,知道了这两个词大概率和什么样的视觉元素绑定。当你输入文字时,模型就会基于这些概率,从最模糊的状态开始,一点点把图像 “猜” 清晰。
不同的文生图模型,比如 Stable Diffusion 和 Midjourney,虽然效果有差异,但核心思路相通:都是先把文字转换成机器能理解的 “语言”,再用这个 “语言” 指导图像的生成。这个过程有点像翻译,只不过是从 “文字语言” 翻译成 “图像语言”。
🔤 第一步:AI 怎么 “读懂” 你的文字?靠的是文本编码
要让 AI 生成符合描述的图像,首先得让它 “明白” 你说的是什么。这一步就交给文本编码器来完成,它的作用相当于 AI 的 “耳朵” 和 “大脑语言中枢”。
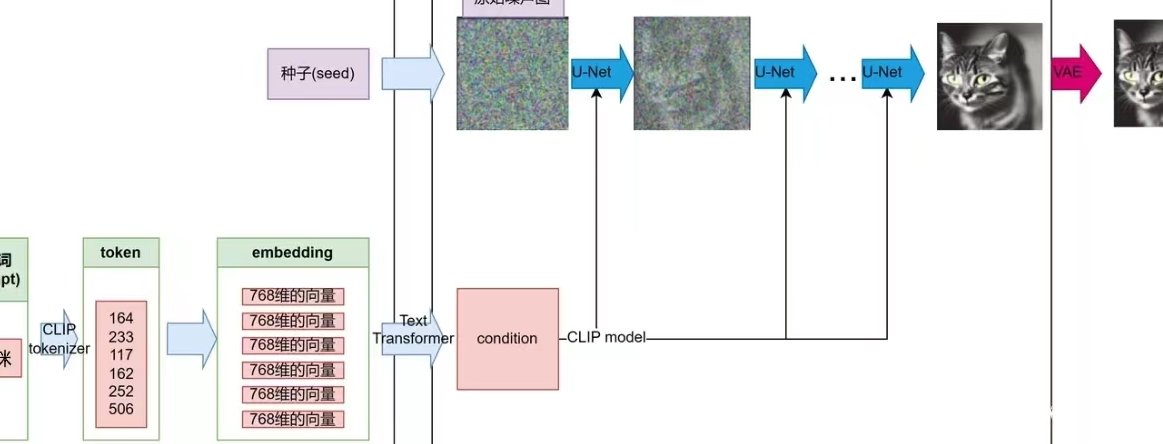
文本编码器的工作原理,简单说就是把文字转换成一串数字(专业叫 “嵌入向量”)。比如你输入 “一只戴着红色帽子的狗”,编码器会把 “狗”“红色”“帽子” 这些关键词拆解开,再转换成机器能处理的数字序列。这些数字不是随便来的,而是通过学习海量文本数据,让每个词都对应到一个独特的数字组合,这个组合里包含了词的含义、属性甚至情感。
现在主流的文生图模型,大多会用到 CLIP(Contrastive Language-Image Pretraining)模型里的文本编码器。CLIP 的厉害之处在于,它不仅能理解文字本身,还能把文字和图像的 “语义” 关联起来。举个例子,它知道 “小狗” 和 “puppy” 在语义上是一回事,也知道 “红色” 对应的视觉特征是什么。这种跨语言、跨模态的理解能力,是 AI 能准确 “读懂” 文字的关键。
但光有文本编码还不够。比如 “红色” 这个词,在不同场景下可能对应不同的色调 —— 是正红、粉红还是深红?这就需要后续的图像生成过程来细化,而文本编码只是给出一个大方向。
🖼️ 第二步:从数字到图像,生成器是怎么 “画” 出来的?
拿到文本编码器输出的数字序列后,就轮到图像生成器登场了。它的任务是根据这些数字,从无到有 “画” 出一张符合描述的图片。目前最主流的生成技术是扩散模型(Diffusion Models),Stable Diffusion、DALL・E 2 都用了这个技术。
扩散模型的工作逻辑很有意思,它不是直接画图像,而是反过来 —— 先从一张全是噪声的图片开始,然后一点点 “擦掉” 噪声,同时根据文本信息添加细节,最后得到清晰的图像。这个过程有点像我们在暗房里洗照片:一开始是模糊的底片,慢慢显影,细节越来越清晰。
具体来说,这个过程分两步:
- 前向扩散:这一步是模型训练时用的。把一张清晰的图片,一步步加入噪声,直到变成完全的噪声图。模型会学习 “加噪” 的规律,知道每一步该加多少噪声,图片会变成什么样。
- 反向扩散:这是生成图片时的步骤。模型从一张随机噪声图开始,根据文本编码的指导,一步步去除噪声。每一步,它都会参考文本信息 —— 比如 “有一只猫”,就会在去噪时往 “猫” 的特征方向调整;“猫是黑色的”,就会把颜色往深色调修正。经过几十甚至上百次迭代后,噪声越来越少,图像也就越来越清晰,最终变成符合描述的样子。
除了扩散模型,早期还有 GAN(生成对抗网络)也被用于文生图,比如最初的 DALL・E。但 GAN 生成的图像质量不稳定,而且很难控制细节,所以现在基本被扩散模型取代了。扩散模型虽然生成速度慢一点,但胜在图像质量高,而且能更好地遵循文本描述。
🧠 关键:怎么保证图像 “符合” 文字?靠跨模态注意力机制
你可能会问,AI 怎么确保生成的图像里,每个细节都和文字对应?比如输入 “左手拿书的女孩”,不会变成 “右手拿书”?这就要靠跨模态注意力机制了,它相当于 AI 的 “聚焦镜”。
注意力机制的作用,是让模型在生成图像时,能 “盯紧” 文本里的关键信息。还是拿 “左手拿书的女孩” 举例:
- 文本编码会突出 “左手”“书”“女孩” 这几个关键词;
- 在图像生成的每一步,模型都会用注意力机制,把这些关键词和图像的对应位置绑定 —— 比如 “女孩” 对应整体的人形轮廓,“书” 对应手上的物体,“左手” 对应身体的左侧肢体;
- 这样一来,模型就不会 “走神”,不会把 “左手” 画成 “右手”,也不会漏掉 “书” 这个元素。
这种机制有点像我们人类画画时的思考:先确定主体是 “女孩”,再加上 “书”,最后调整 “左手” 的姿势。AI 虽然没有 “思考”,但通过注意力机制,能模拟这种聚焦关键信息的过程。
📊 背后的功臣:海量训练数据
所有这些技术能跑通,离不开海量的图文对训练数据。没有数据,再牛的模型架构也没用。
文生图模型的训练数据,是上亿甚至几十亿对 “文字 - 图像” 组合。这些数据来自互联网上的图片和它们的描述文字 —— 比如博客里的配图、电商网站的商品图和说明、社交媒体上的图文动态等。模型在训练时,会一遍遍地看这些数据,学习 “文字描述 A 对应图像 B” 的规律。
举个例子,当模型看过几万张 “猫” 的图片,以及对应的 “猫”“小猫”“黑色的猫” 等文字后,就会慢慢总结出:“猫” 通常有四条腿、一条尾巴、毛茸茸的;“黑色” 对应的像素颜色是深色调。当训练数据足够多、足够多样时,模型就能应对各种复杂描述 —— 哪怕是它从没见过的组合,比如 “一只长着翅膀的紫色猫”,也能根据 “翅膀”“紫色”“猫” 这些单独元素的规律,生成合理的图像。
但数据质量很关键。如果训练数据里有错误 —— 比如把 “狗” 的图片标成了 “猫”,模型就会学到错误的规律,生成的图像也会出错。所以,高质量、无错误的训练数据,是文生图模型准确工作的基础。
🛠️ 模型怎么 “学” 会这些?预训练 + 微调的两步走
文生图模型的 “学习” 过程,一般分两步:预训练和微调。
预训练是 “打基础” 的阶段。模型会在海量的图文数据上进行训练,目标是掌握通用的规律 —— 比如什么是 “动物”,什么是 “颜色”,文字和图像的基本对应关系。这个阶段训练时间长、成本高,需要巨大的计算资源,但能让模型具备基本的 “理解” 和 “生成” 能力。
预训练之后,会进行微调。比如针对特定场景(如二次元绘画、产品设计),用更专业的数据集训练模型,让它在这些领域表现更好。有些模型还支持用户自己上传数据微调,比如 Stable Diffusion 的 LoRA(Low-Rank Adaptation)技术,能让模型快速学会特定风格或特定物体的生成。
这种两步走的方式,既能让模型具备通用能力,又能适应不同的细分需求,这也是为什么现在有那么多基于 Stable Diffusion 的衍生模型 —— 有的擅长画真人,有的擅长画风景,有的能精准还原动漫风格。
❓ 为什么有时生成的图像会 “跑偏”?
用过文生图工具的人可能遇到过:输入的文字明明是 “一只站在树上的鸟”,生成的却是 “一只鸟站在屋顶上”。这是怎么回事?
主要有几个原因:
- 文本描述不够精确:如果文字里没有明确 “树” 的特征(比如 “松树”“苹果树”),模型可能会用更常见的 “屋顶” 来替代,因为训练数据里 “鸟站在屋顶” 的案例可能更多。
- 模型理解有局限:对于一些抽象、复杂或罕见的描述,比如 “一种从未见过的、长着鳞片的花”,模型很难准确生成,因为训练数据里没有类似的样本,它缺乏参考依据。
- 随机性影响:扩散模型生成图像时,每一步都有一定的随机性。即使输入相同的文字,两次生成的图像也可能有差异,有时这种随机性会导致细节 “跑偏”。
要减少这种情况,除了优化模型本身,用户也可以通过更精确的描述(比如加入更多细节词)、调整参数(如提高生成步数)来改善结果。
总结一下
文生图模型能 “看懂” 文字并生成图片,核心是三个环节:
- 用文本编码器把文字转换成机器能理解的数字序列;
- 用扩散模型(或其他生成模型),根据这些数字序列,从噪声开始一步步生成图像;
- 靠跨模态注意力机制和海量训练数据,确保图像和文字描述对应。
这背后是自然语言处理、计算机视觉、深度学习等多领域技术的融合。现在的文生图模型虽然还有不足,但已经能完成很多以前只有人类创作者才能做到的事。随着技术的进步,未来的 AI 可能会更 “懂” 人类的想法,生成的图像也会越来越精准、越来越有创造力。
【该文章由diwuai.com第五 ai 创作,第五 AI - 高质量公众号、头条号等自媒体文章创作平台 | 降 AI 味 + AI 检测 + 全网热搜爆文库
🔗立即免费注册 开始体验工具箱 - 朱雀 AI 味降低到 0%- 降 AI 去 AI 味】
🔗立即免费注册 开始体验工具箱 - 朱雀 AI 味降低到 0%- 降 AI 去 AI 味】















