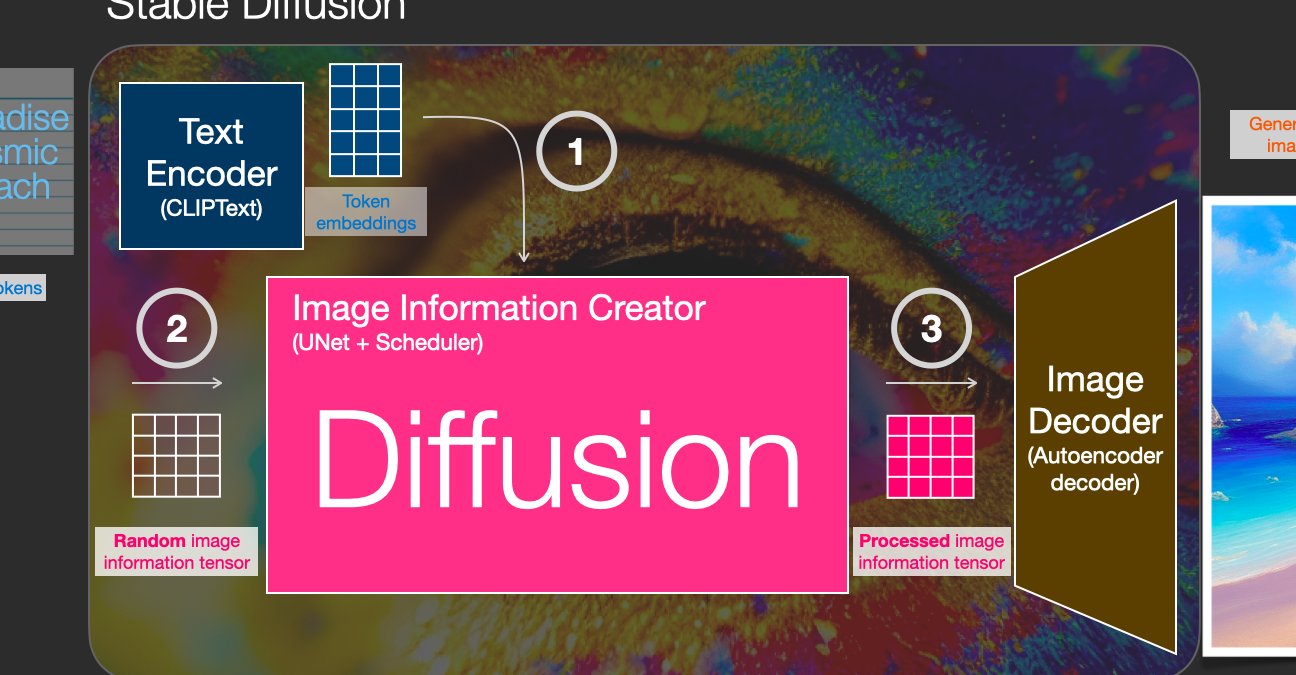
🚀 模型选择:别在 "选装备" 上浪费时间
很多人刚接触 Stable Diffusion 时,总觉得模型越多越好,文件夹里塞了上百个模型,出图时反而不知道该用哪个。大神们的做法刚好相反 ——只保留 3-5 个核心模型,每个模型专攻一类风格。
比如做写实人像,就固定用 RealVisXL 或 Juggernaut;想要二次元风格,Counterfeit-V3 和 MeinaMix 足够应对 80% 的场景。这些模型经过大量测试,参数兼容性强,出图稳定。他们会建一个简单的 Excel 表格,记录每个模型的最佳适用场景:比如 "ChilloutMix 适合柔光人像,Cetus-Mix 擅长硬光机械风",避免每次都靠感觉选模型。
模型更新也不用追新,除非新模型能解决现有痛点。上个月看到有人为了试一个所谓的 "全能模型",花 3 小时重新测试参数,结果出图效果和旧模型差距不大。稳定的模型库 + 固定参数组合,才能让效率翻倍。
📝 提示词工程:3 层结构法快速出效果
提示词不是越长越好,大神们的提示词通常控制在 80-120 个字符,却能精准传达画面要素。他们用的是 "主体 + 风格 + 细节" 的三层结构。
主体部分明确核心元素,比如 "a girl in red dress, standing in rain",不需要修饰词;风格部分加艺术流派或参考艺术家,像 "by Greg Rutkowski, impressionism";细节部分聚焦光影和质感,例如 "soft shadow, 8k, cinematic lighting"。
反向提示词更简单,固定用 "lowres, bad anatomy, text, watermark" 这几个高频词,最多根据场景加 1-2 个针对性词汇。有个小技巧:把常用提示词做成模板,比如写实模板、二次元模板,出图时只改主体部分,30 秒就能搞定提示词。
见过最夸张的案例,有人用同一个基础模板,每天能出 500 + 张合格的商业图,核心就是把提示词的创作成本降到最低。
⚙️ 参数设置:记住这组 "黄金比例"
参数调不对,要么出图慢,要么效果差。大神们的参数表其实很固定,采样方法首选 Euler a 或 DPM++ 2M Karras,这两种在速度和质量间平衡最好。
迭代步数不是越多越好,写实风格 25-30 步,二次元 20-25 步足够了。超过 40 步后,细节提升不明显,但出图时间会增加一倍。分辨率常用 1024x768 或 768x1280,这个尺寸既能保证细节,又不会让显卡过载。
CFG Scale 控制 AI 对提示词的遵循度,一般设 7-9。低于 5 容易跑题,高于 12 会让画面僵硬。很多人喜欢调一堆参数测试,其实没必要,先固定这几个核心参数,出图效果不满意再微调。
硬件不够的话,记得开 xFormers 加速,显存占用能降 30%。有个工作室的电脑配置一般,但用这套参数,出一张 1024 分辨率的图只要 40 秒,比同配置的人快一倍。
🔄 迭代优化:2 步法则快速修图
出图不是一次性的,大神们都会留 10% 的时间做迭代。但他们的迭代很有针对性,不是盲目重绘。
第一步用图生图功能做整体优化。把初图拖进去,重绘幅度设 0.3-0.5,提示词加几个需要强化的细节,比如初图光影弱,就加 "volumetric lighting"。这一步能在保留整体构图的前提下优化细节。
第二步用局部重绘处理瑕疵。比如手部变形,就用 mask 圈出手部,重绘幅度设 0.7,提示词补充 "five fingers, natural hand position"。局部重绘时,迭代步数可以降到 15-20 步,因为只需要优化小区域,步数多了反而容易出问题。
见过一个画师处理复杂场景,先用全局迭代 3 次,再局部优化 5 个区域,全程不到 10 分钟,比从头重绘效率高太多。
📦 批量处理:脚本 + 插件解放双手
单张出图效率再高,也赶不上批量处理。大神们常用两种批量方法:Stable Diffusion 自带的脚本功能和第三方插件。
用脚本的话,在 txt2img 界面选 "Prompts from file or textbox",把准备好的提示词列表复制进去,设置好参数就能批量生成。适合需要多组不同主体的场景,比如一次性生成 10 个不同姿势的角色。
如果需要统一风格的系列图,就用 ControlNet 插件的批量处理功能。先做好一张参考图,设置好 OpenPose 或 Canny 参数,然后导入需要处理的图片文件夹,AI 会自动按参考图的风格和结构生成批量图片。
批量出图时,分辨率可以先设 512x512,快速筛选出合适的构图后,再用高清修复功能放大到 1024x1024。这样既能提高筛选效率,又能节省显卡资源。
✂️ 后期衔接:AI 出图 + PS 修图无缝对接
真正的高效工作流,不会让 AI 做完所有事。大神们的习惯是:Stable Diffusion 负责出主体画面,Photoshop 或 GIMP 处理细节和排版。
出图时会特意保留一些 "可编辑空间",比如人物边缘留 10% 的模糊度,方便后期调整。用图生图功能时,会把重绘幅度设 0.5 左右,让 AI 保留部分原始细节,减少后期修复工作量。
有个进阶技巧:用 Stable Diffusion 生成 3-5 张同场景不同细节的图,然后在 PS 里用图层混合模式叠加,快速融合不同图的优点。比如把 A 图的光影、B 图的细节、C 图的色彩融合在一起,比单张优化快 3 倍。
别小看后期衔接的效率,有个做电商图的团队,就是靠 AI 出图 + PS 批量处理,把每日出图量从 30 张提到了 200 张,核心就是把两个工具的优势都发挥到极致。
说到底,高效出图的核心不是掌握多少技巧,而是形成自己的固定流程。从模型选择到后期处理,每个环节都固定下来,只在必要时做微调,才能把时间花在创意上,而不是反复试错上。刚开始可能觉得死板,但练熟后,出图效率至少能提升 5 倍 —— 这就是为什么同样用 Stable Diffusion,有人一天出 10 张图,有人能出 50 张。
【该文章由diwuai.com第五 ai 创作,第五 AI - 高质量公众号、头条号等自媒体文章创作平台 | 降 AI 味 + AI 检测 + 全网热搜爆文库
🔗立即免费注册 开始体验工具箱 - 朱雀 AI 味降低到 0%- 降 AI 去 AI 味】
🔗立即免费注册 开始体验工具箱 - 朱雀 AI 味降低到 0%- 降 AI 去 AI 味】















