朱雀大模型的判定标准是基于多维度的技术指标和场景化评估体系构建的。从技术层面看,它主要通过分析文本的困惑度(Perplexity)和爆发性(Burstiness)等核心参数来判断内容是否由 AI 生成。困惑度衡量的是文本的可预测性,AI 生成的内容通常语言模式更标准,困惑度较低;而爆发性指句子长度和结构的变化,人类写作往往长短句结合,结构更灵活,AI 生成的文本则容易出现句式单一、长度均匀的问题。
在实际应用中,朱雀大模型的判定标准还会根据不同场景进行调整。比如在新闻、学术等结构性强的领域,会重点关注专业术语的使用频率和行文规范度,这类文本如果语言模式过于工整,即使是人工撰写也可能被误判为 AI 生成。像官方新闻稿、学术论文这类内容,由于逻辑严密、用词规范,很容易触发检测系统的敏感阈值,导致误判率上升。
2025 年升级后,朱雀大模型在判定标准上有了显著优化。一方面引入了中文语义熵模型,通过分析词汇分布的随机性来破解 “人类语言随机性” 密码,有效降低了因文本规范性导致的误判。另一方面,新增了诗歌体裁检测支持,提升了对复杂文本的识别能力,尤其是在处理文学创作中意象组合、情感连贯性等方面的表现更加精准。此外,升级后的模型还拓展了多模态检测能力,除了文本检测,还能识别 AI 生成的图像和视频,覆盖了 Midjourney、Stable Diffusion 等主流生成模型。
不过,升级后的朱雀大模型在误判率问题上仍存在一定挑战。从实际测试数据来看,其整体误判率虽然控制在 12% 以下,但在不同场景下表现差异较大。比如在中文检测中,准确率为 72.4%,而英语检测准确率高达 98%,这种语言差异导致的误判问题依然存在。对于人工撰写的学术论文,朱雀的检测准确率较高,但像茅茅虫这类工具误判率却超过九成,这说明不同工具的判定标准存在较大差异。
在多模态检测方面,朱雀大模型对 AI 生成的图片识别能力较强,但对经过二次编辑的图片仍容易误判。例如一张经过 PS 修改的风景图,就可能被错误地判定为 AI 生成,这暴露出局部修改图片识别的技术难点。此外,用户反馈中提到,一些文风华丽、用词考究的原创内容,尤其是带有科幻、玄幻等风格的文学作品,容易被误判为 AI 生成。比如方文山为邓紫棋新书撰写的推荐语,因使用了 “凌晨三点的第一缕阳光” 等富有想象力的表述,被朱雀检测为 AI 浓度 100%,但删除标题和作者信息后,检测结果降至 37.05%,这种前后差异反映了检测系统对特定表述的敏感。
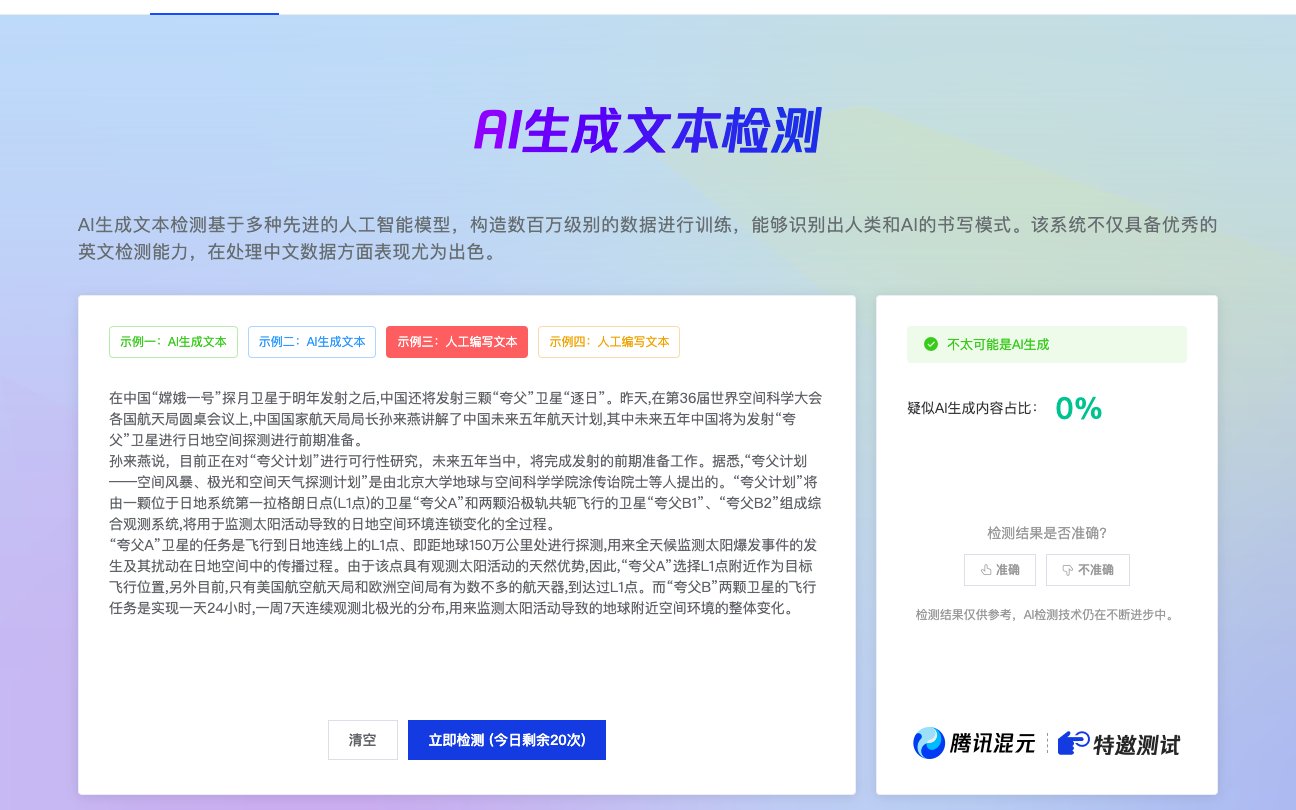
针对误判率问题,朱雀大模型的技术团队采取了多项优化措施。一是通过每日更新 10 万条生成样本训练数据,建立动态进化机制,不断迭代模型以适应新的生成模式。二是优化了检测引擎,能够精准标记可疑内容并提供详细报告,帮助用户定位误判原因。例如检测结果会显示人工占比、AI 占比及疑似 AI 占比,并附有评估说明,方便创作者针对性地调整内容。三是加强了对中文语境的适配,通过分析国内常见 AI 写作工具的特征,提升了对文心一言、混元等模型生成内容的识别准确率。
对于用户来说,要降低被误判的风险,需要了解朱雀大模型的判定逻辑。首先,在撰写结构性强的文本时,可以适当加入一些个性化表达,避免语言模式过于工整。比如在学术论文中,可以增加一些研究过程的细节描述,或者加入个人思考的片段,让文本更具 “人味”。其次,对于文学创作,尤其是诗歌、散文等体裁,要注意情感连贯性和意象组合的合理性,避免因过度追求华丽辞藻而触发检测系统的敏感点。此外,使用朱雀检测工具时,可以尝试分段落检测,或者删除标题、作者信息等可能影响判断的元素,以获得更准确的结果。
总的来看,朱雀大模型的判定标准在 2025 年升级后更加全面和智能,通过多维度的技术优化和场景化适配,有效提升了检测的准确性。尽管误判率问题尚未完全解决,但随着动态进化机制的不断完善和多模态检测能力的拓展,其在 AI 内容识别领域的可靠性正在逐步增强。对于创作者和内容平台来说,了解这些判定标准和优化方向,能够更好地应对 AI 检测带来的挑战,在保证内容质量的同时,降低被误判的风险。
该文章由diwuai.com第五 ai 创作,第五 AI - 高质量公众号、头条号等自媒体文章创作平台 | 降 AI 味 + AI 检测 + 全网热搜爆文库
🔗立即免费注册 开始体验工具箱 - 朱雀 AI 味降低到 0%- 降 AI 去 AI 味
🔗立即免费注册 开始体验工具箱 - 朱雀 AI 味降低到 0%- 降 AI 去 AI 味















