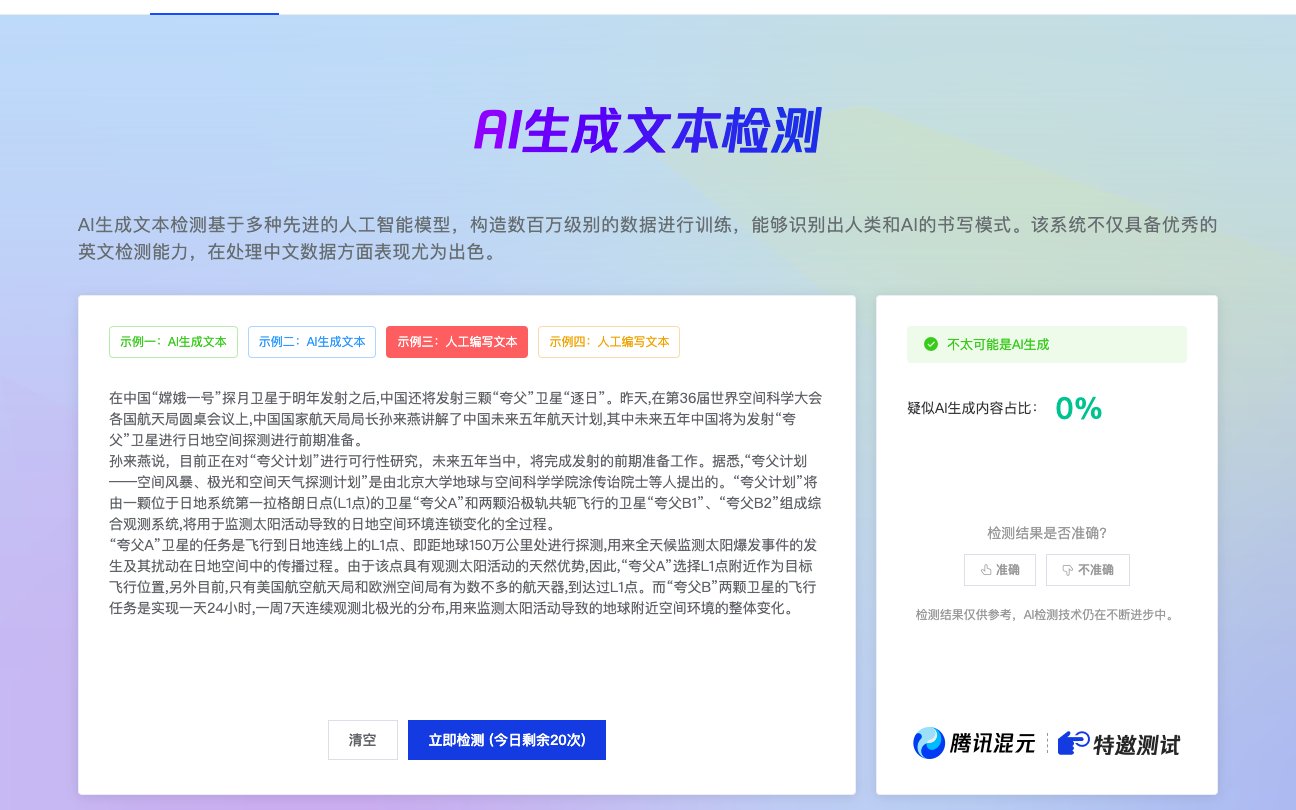
🔍 基于特征分析的大模型文本检测
大模型生成的文本往往带着独特的 “印记”,这些印记就是检测的突破口。从用词来看,大模型可能会高频使用某些特定词汇,尤其是那些听起来比较 “通用”“中性” 的词,比如 “综上所述”“然而”“因此” 等,人类写作时反而不会这么有规律。句子结构上,大模型写的句子通常比较规整,长短变化不大,不像人类会根据表达需求随意调整,有时长句拉得很长,有时短句干脆利落。
还有标点符号的使用,大模型对逗号、句号的运用可能过于 “标准”,很少出现人类写作中那种为了强调或者语气停顿而出现的不那么规范的用法。检测工具会把文本拆解开,像解剖一样分析这些特征,统计词汇频率、句子长度分布、标点使用规律等。要是这些数据和大模型的 “模板” 高度吻合,那文本就很可能是 AI 生成的。
不过这种方法也有局限,要是有人刻意模仿大模型的特征写文本,或者大模型本身经过了优化调整,特征没那么明显,就可能出现误判。
📊 基于模型对比的大模型文本检测
这种方法就像是给文本 “验明正身”。原理是拿待检测的文本和已知的大模型生成文本库进行对比。检测工具会计算两者的相似度,包括语义上的、结构上的。如果相似度超过一定阈值,就会判定为大模型生成。
具体操作中,会先建立一个庞大的大模型文本数据库,涵盖不同类型、不同主题的内容。检测时,把要检测的文本输入进去,系统会自动在数据库里找 “亲戚”。比如一篇关于科技的文章,要是和数据库里某篇 GPT 生成的科技文相似度特别高,那结果就很明显了。
但这种方法依赖于数据库的丰富程度,如果数据库里没有类似的文本,检测准确性就会下降。而且对于经过深度修改的大模型文本,也容易出现判断失误。
🧠 基于语义理解的大模型文本检测
大模型生成的文本可能在语义连贯性上存在 “短板”。人类写作时,上下文之间的逻辑跳转可能更灵活,有时看似不相关的内容,其实有潜在的联系。但大模型为了保证逻辑通顺,可能会过度追求上下文的 “严丝合缝”,反而显得生硬。
基于语义理解的检测方法,会深入分析文本的上下文逻辑、情感变化、观点连贯性。比如一篇人类写的影评,可能会突然联想到自己的类似经历,然后再拉回对电影的评价,这种跳跃在大模型文本里就比较少见。
检测工具会给文本的语义连贯性打分,分数过低就可能被判定为 AI 生成。但这种方法对检测工具的语义理解能力要求很高,要是工具本身理解不了某些复杂的语义跳转,也会出现误判。
⚙️ 基于溯源追踪的大模型文本检测
有些大模型在生成文本时,会留下特殊的 “数字指纹”,就像人的签名一样。基于溯源追踪的检测方法,就是通过技术手段寻找这些指纹。比如某些大模型会在文本的元数据里留下生成信息,或者在特定位置嵌入只有该模型能识别的标记。
检测人员可以借助专门的工具解析文本的元数据,或者用算法扫描文本,寻找这些隐藏的标记。如果找到了,就能确定文本来自哪个大模型。这种方法的准确性比较高,但前提是要掌握各个大模型的 “指纹” 特征。
一旦大模型更新迭代,修改了这些指纹,那这种检测方法就会失效,需要不断更新数据库来应对。
🎯 朱雀 AI 检测误判:文本风格特殊导致的误判及解决
有时候朱雀 AI 会把一些风格独特的人类文本误判成大模型生成的。比如有些作家喜欢用极简的短句,一句一个字或者几个字,读起来很有韵味,但朱雀 AI 可能会觉得这种过于规整的短句不符合人类写作的 “随意性”,从而误判。
解决这种误判,可以适当调整文本风格。在不破坏整体表达的前提下,把一些过短的句子合并,增加一些长短句的变化。比如把 “风。雨。人。” 改成 “风夹着雨,打在人的脸上。” 同时,加入一些口语化的表达,像 “呢”“啊”“吧” 之类的语气词,让文本更贴近人类日常说话的感觉。
还可以在文本中加入一些个人化的小细节,比如自己的感受、经历等。比如写一篇游记,不只是描述风景,再加上一句 “当时看到那棵树,突然想起小时候爬树摔下来的事,现在想想还觉得疼呢”,这样的个人化内容能降低误判的概率。
📚 朱雀 AI 检测误判:专业领域内容导致的误判及解决
专业领域的文本,比如医学、法律、科技等,往往包含大量专业术语,句子结构也比较复杂严谨。朱雀 AI 可能会因为这些文本 “太专业”“太规整” 而误判。
要解决这个问题,首先可以在文本中适当增加一些解释性的话语。比如提到一个专业术语,后面加一句通俗的解释,像 “‘房室传导阻滞’,简单说就是心脏的电信号传导出了问题”。这样既能保证专业性,又能让文本多一些人类解释的痕迹。
其次,可以在文本里加入一些行业内的 “行话” 或者 “俗语”。每个专业领域都有自己的非正式表达,这些表达在大模型生成的文本里比较少见。比如在法律文本里,适当用一些律师之间常用的简化说法,能让文本更 “有人味”。
另外,提交检测时,可以附上相关的专业背景说明,告诉朱雀 AI 这是专业领域的文本,有其特殊性,帮助 AI 更准确地判断。
🔄 朱雀 AI 检测误判:内容长度异常导致的误判及解决
有些时候,文本过长或者过短也会导致朱雀 AI 误判。比如一篇几百字的短文,内容精炼,没有多余的话,朱雀 AI 可能会觉得太 “完美”,不像人类写的;而一篇几万字的长文,结构严谨,逻辑清晰,也可能被误判。
对于过短的文本,可以适当增加一些铺垫性的内容。比如写一篇推荐一本书的短文,不只是说 “这本书好,推荐”,再加上几句为什么会看到这本书,拿到书时的第一感觉等内容,增加文本的 “厚度”。
对于过长的文本,可以在其中加入一些 “小插曲”。比如在一篇长篇技术分析文中,插入一句 “写到这里,突然想起上次开会时同事对这个问题的不同看法,虽然和现在说的关系不大,但觉得挺有意思”,这样的小插曲能打破过于严谨的结构,减少误判。
同时,注意文本的段落划分,不要把内容都堆在一个段落里,适当拆分,让段落长度更符合人类阅读的习惯,也能降低误判的可能。
🗣️ 朱雀 AI 检测误判:申诉与沟通解决误判
如果尝试了各种方法还是被朱雀 AI 误判,那就可以通过申诉来解决。首先要收集好证据,证明文本是人类创作的。比如创作过程中的草稿、修改记录、灵感来源的笔记等,这些都能说明文本的创作轨迹是人类的思维过程。
然后,按照朱雀 AI 平台的申诉流程提交材料。在申诉说明里,详细解释文本的创作背景、个人的写作风格、包含的个人化内容等,让审核人员更全面地了解文本情况。
申诉时语气要诚恳,态度要专业。可以说 “我这篇文本确实是自己写的,里面有我个人的经历和感受,可能是风格比较特殊才被误判,希望能重新审核一下”。一般来说,只要证据充分,说明合理,平台都会重新审核,纠正误判。
另外,还可以加入朱雀 AI 的用户交流群,和其他用户交流遇到的误判问题,学习他们的解决经验。也可以直接和平台的客服沟通,反馈误判情况,帮助平台不断优化检测算法。
大模型文本检测和朱雀 AI 检测误判的问题,其实是技术发展过程中必然会遇到的。作为创作者,既要了解检测的原理和方法,提前规避一些可能被误判的因素,也要知道在遇到误判时该如何解决。随着技术的不断进步,相信这些检测工具会越来越精准,误判的情况也会越来越少。但在这之前,掌握这些方法和技巧,能让我们的创作之路更顺畅。
【该文章由diwuai.com
第五 ai 创作,第五 AI - 高质量公众号、头条号等自媒体文章创作平台 | 降 AI 味 + AI 检测 + 全网热搜爆文库🔗立即免费注册 开始体验工具箱 - 朱雀 AI 味降低到 0%- 降 AI 去 AI 味】




的探店号市场如何?")










