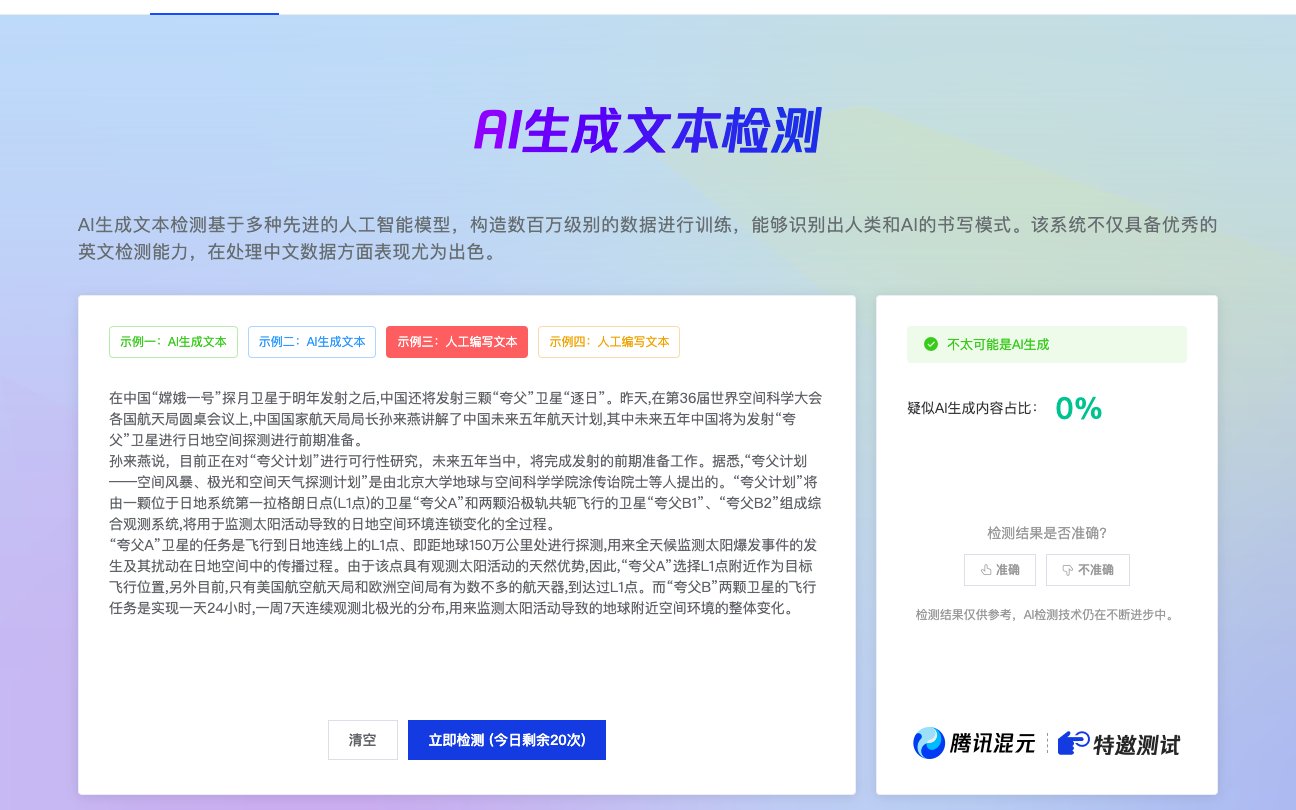
大家对朱雀大模型的 AI 检测功能越来越关注,毕竟现在内容创作里,原创性太重要了。但用着用着,问题也跟着冒出来。今天就好好聊聊朱雀大模型 AI 检测的常见问题,把它的工作原理和准确率掰开了揉碎了说清楚。
🤔 朱雀大模型 AI 检测到底是怎么干活的?
想搞懂朱雀大模型的 AI 检测,得先明白它的底层逻辑。简单说,它就像个经验丰富的 “文字侦探”,靠着庞大的数据库和复杂的算法模型,给文字 “把脉”。
它会把待检测的文本拆成一个个小单元,比如词语、句子结构,甚至是标点符号的使用习惯。然后拿这些单元和数据库里的 AI 生成文本特征做比对。这些特征包括特定的句式偏好、重复出现的表达模式,还有那些人类很少用的逻辑衔接方式。
打个比方,人类写东西的时候,可能会突然插入一句无关紧要的感慨,或者在描述一件事的时候,不经意间加入个人经历的小细节。但 AI 生成的内容,往往逻辑过于工整,少了这种 “随性”。朱雀大模型就是靠捕捉这些差异,来判断文本是不是 AI 写的。
而且它的算法一直在更新,跟着市面上主流 AI 工具的生成特点变。今天能识别出 ChatGPT 的套路,明天可能就对文心一言的表达方式了如指掌。这也是为啥很多人觉得它检测得越来越准的原因。
📊 检测准确率到底靠谱不?为啥有时候会不准?
不少人用了朱雀大模型的 AI 检测后,都会纠结准确率的问题。说实话,它的准确率在同类工具里算高的,但也不是 100% 没毛病。
一般情况下,对于那种纯粹由 AI 生成、没经过任何人工修改的文本,它的识别率能到 90% 以上。比如用 AI 写的新闻通稿、产品说明,结构规整,套路明显,一测一个准。
可要是遇到 “人机混写” 的内容,就容易出岔子了。有人把 AI 生成的内容改改句式,加几句自己的话,朱雀大模型可能就会误判。之前有个朋友,用 AI 写了篇游记初稿,自己又加了很多旅途中的细节感受,结果检测出来说有 70% 是 AI 生成的,其实他改的部分占了大半。
还有就是文本长度的影响。太短的文本,比如一两百字,特征不明显,检测结果就容易波动。有次我拿一段 50 字的广告语去测,第一次说有 AI 痕迹,隔了半小时再测,又说更像人类创作,这就是因为短文本的特征点太少,算法不好下判断。
另外,不同类型的文本,检测准确率也不一样。散文、诗歌这类主观性强、表达方式灵活的文本,AI 生成的特征相对模糊,朱雀大模型有时候会 “拿不准”;而像学术论文、技术文档这种逻辑性强、格式严谨的文本,AI 生成的特征更明显,检测起来就准得多。
🔍 检测结果里的 “AI 概率” 是啥意思?怎么看才对?
打开朱雀大模型的检测报告,最显眼的就是那个 “AI 概率” 数值。有人觉得这个数越高,就说明文本越可能是 AI 写的,其实没这么简单。
这个概率是算法根据文本特征,综合计算出来的一个参考值,代表的是文本与已知 AI 生成内容的相似程度。比如概率 60%,意思是这段文本有 60% 的特征和 AI 生成的内容吻合,不是说有 60% 的内容是 AI 写的。
别光盯着数字看,得结合下面的 “特征分析”。有的文本 AI 概率 70%,但特征分析里说主要是因为句式太规整;有的概率 50%,却是因为出现了很多 AI 常用的高频词汇。这两种情况,显然前者更值得注意,因为句式规整是 AI 生成的典型特征,而高频词汇可能只是巧合。
还有人遇到过这种情况:同一段文本,两次检测的 AI 概率差了 10% 以上。这不是工具出问题了,可能是检测时算法刚好在微调,或者数据库更新了小部分内容。这种波动在合理范围内,只要不是差得太离谱,不用太较真。
看检测结果的时候,得有自己的判断。如果 AI 概率超过 80%,同时特征分析里列举了多条明显的 AI 生成特征,那这段文本大概率是 AI 写的;如果概率在 50% 左右,特征又不明显,最好自己再通读一遍,结合内容的逻辑性、情感表达来判断。
💡 哪些因素会干扰检测结果?该怎么避免?
想让朱雀大模型的检测结果更准,就得知道哪些因素会干扰它,尽量避开。
首先是文本里的特殊符号和格式。有次我把一段带很多 emoji 的文案放进去检测,结果 AI 概率一下升高了不少。后来才发现,很多 AI 生成内容会频繁用 emoji 来增强表达,算法把这个当成了一个特征点,而我那段文案里的 emoji 是自己加的,纯属巧合。所以检测前,最好把不必要的特殊符号去掉。
其次是引用内容过多。如果文本里有大段引用别人的话,尤其是引用那些本身可能是 AI 生成的内容,就会干扰检测。之前有个自媒体作者,在文章里引用了一段 AI 写的名人名言,结果整篇文章的检测结果都受了影响,其实他自己写的部分占了大部分。所以引用内容最好标出来,或者检测时把纯引用的部分暂时去掉。
还有就是语言风格的问题。如果一个人平时写东西就很 “死板”,句式工整、逻辑严谨,和 AI 生成的风格很像,那他的文本可能会被误判。这种情况没办法改变,只能是检测后结合自己的创作过程来判断,别完全依赖工具结果。
另外,检测时的网络环境也可能有影响。网络不稳定的时候,文本上传可能会出现部分丢失,导致检测的是不完整的文本,结果自然就不准了。所以检测的时候,最好确保网络通畅,等文本完全上传成功后再开始检测。
🆚 和其他 AI 检测工具比,朱雀大模型有啥不一样?
市面上的 AI 检测工具不少,朱雀大模型能站稳脚跟,肯定有它的过人之处。
最明显的是更新速度快。每次有新的主流 AI 工具出来,比如之前 Claude 3 发布后,没过多久朱雀大模型就更新了算法,能识别出 Claude 3 生成内容的特征。而有些工具,可能要一两个月才更新一次,对新 AI 生成的内容就 “束手无策”。
然后是对中文文本的适配更好。很多国外的检测工具,对中文的表达方式理解不深,容易把一些有中国特色的表达当成 AI 生成的。比如 “给力”“打工人” 这些网络热词,国外工具可能觉得很突兀,判断成 AI 痕迹,而朱雀大模型对这些词的识别就准确得多,因为它的数据库里有大量中文网络用语样本。
还有就是检测报告更详细。不光给个 AI 概率,还会把具体的可疑句子标出来,告诉用户这些句子哪里像 AI 写的,是句式问题还是用词问题。有次我用另一个工具检测,只说文本有 AI 痕迹,却指不出具体哪里有问题,改都不知道从哪儿下手,朱雀大模型就没这毛病。
不过它也有不如别人的地方。比如检测速度,比起一些轻量级的工具,朱雀大模型因为要处理更多特征点,速度会慢一点。检测一篇 5000 字的文章,可能要等个一两分钟,而有的工具几十秒就出结果了。
❓ 用朱雀大模型检测时,常见的操作误区有哪些?
别看朱雀大模型操作起来不复杂,但很多人用的时候会踩坑,影响检测效果。
最常见的就是直接拿 PDF 或者图片里的文本去检测。朱雀大模型目前主要支持纯文本输入,如果你把 PDF 里的内容复制粘贴过去,可能会带上一些格式代码,这些代码会干扰算法判断。有个同事就犯过这错,检测结果一直不准,后来发现是粘贴的时候带了很多 PDF 的隐藏格式,去掉之后结果就正常了。
还有人喜欢频繁多次检测同一段文本。其实短时间内多次检测,结果不会有太大变化,反而可能因为服务器缓存,出现和第一次一样的结果,浪费时间。最好是修改文本后,隔一段时间再检测,让算法重新分析。
另外,完全相信检测结果,不自己判断,这也是个大误区。工具只是辅助,最终还是得靠人来判断。有个学生写论文,自己原创的部分被朱雀大模型误判有 AI 痕迹,他就慌了,大改特改,结果改得乱七八糟,其实他只要结合自己的创作过程,就知道工具结果不对。
还有就是不看检测报告里的 “温馨提示”。朱雀大模型会根据检测结果给出一些建议,比如 “文本偏短,结果仅供参考”“存在较多引用内容,建议去除后重测”,这些提示能帮你更准确地理解结果,可很多人直接忽略,只看那个 AI 概率,这就有点本末倒置了。
🌟 以后朱雀大模型的 AI 检测会有啥新变化?值得期待不?
从目前的发展趋势来看,朱雀大模型的 AI 检测功能肯定会越来越强,值得大家期待。
首先是对 “深度人机混写” 的识别能力会提升。现在很多人把 AI 生成的内容改得很隐蔽,朱雀大模型接下来可能会引入更精细的特征分析,比如分析用词的情感波动、逻辑的跳跃性,这些人类创作中更细微的特征,让 “混写” 内容无所遁形。
然后可能会增加更多个性化设置。比如可以让用户选择检测的侧重点,是更关注句式还是用词,或者针对不同的创作领域,比如自媒体、学术研究,提供不同的检测模式。这样一来,检测结果会更符合用户的实际需求。
还有就是检测速度会优化。现在检测长文本有点慢,之后可能会采用更高效的算法,在保证准确率的前提下,缩短检测时间。想想看,以后检测一篇万字长文,几分钟就能出详细报告,多方便。
不过也有需要注意的地方,随着 AI 生成技术的进步,AI 生成的内容会越来越像人类创作,朱雀大模型和 AI 生成技术之间的 “较量” 会一直持续。但不管怎么说,只要它能跟上节奏,不断更新迭代,就依然是我们判断内容原创性的好帮手。
总的来说,朱雀大模型的 AI 检测功能有它的优势,也有需要完善的地方。我们用的时候,得了解它的工作原理,知道怎么看检测结果,避开那些操作误区,这样才能让它更好地为我们服务。毕竟工具是死的,人是活的,合理利用,才能发挥它的最大价值。
【该文章由diwuai.com第五 ai 创作,第五 AI - 高质量公众号、头条号等自媒体文章创作平台 | 降 AI 味 + AI 检测 + 全网热搜爆文库
🔗立即免费注册 开始体验工具箱 - 朱雀 AI 味降低到 0%- 降 AI 去 AI 味】
🔗立即免费注册 开始体验工具箱 - 朱雀 AI 味降低到 0%- 降 AI 去 AI 味】















