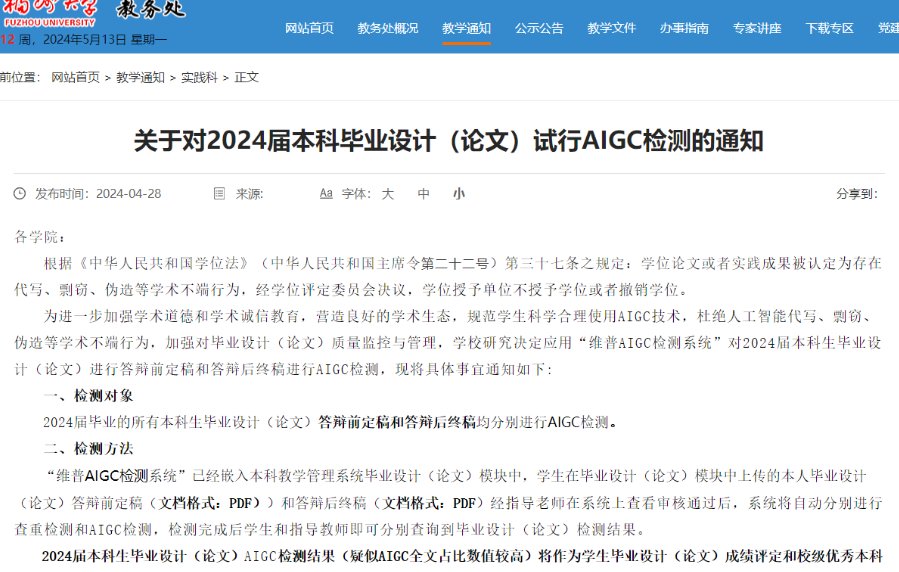
🔥 2025 AI 检测系统的核心升级点
2025 年的 AI 检测系统在技术底层发生了根本性变革,尤其在数据库覆盖和语义分析能力上有了质的飞跃。以 Turnitin 为例,其数据库新增了 200 多亿网页资源和 1.5 亿篇学生论文库,形成了 “全球学术 + 本地资源” 的双重比对网络。中国知网则通过 AI 增强检索功能,实现了从关键词匹配到语义向量检索的范式革新,能够识别段落级别的上下文关联。更关键的是,检测系统开始关注写作过程的 “人性化痕迹”,比如修改时间戳、版本迭代记录等,单纯依靠同义词替换的传统降重方法已经失效。
2025 年的 AI 检测系统在技术底层发生了根本性变革,尤其在数据库覆盖和语义分析能力上有了质的飞跃。以 Turnitin 为例,其数据库新增了 200 多亿网页资源和 1.5 亿篇学生论文库,形成了 “全球学术 + 本地资源” 的双重比对网络。中国知网则通过 AI 增强检索功能,实现了从关键词匹配到语义向量检索的范式革新,能够识别段落级别的上下文关联。更关键的是,检测系统开始关注写作过程的 “人性化痕迹”,比如修改时间戳、版本迭代记录等,单纯依靠同义词替换的传统降重方法已经失效。
🛠️ 内容改写的 5 大黄金法则
1. 结构重组法
使用 “对比式提示词” 替代直接生成,例如 “请对比 A 学者和 B 学者在 XX 问题上的研究方法差异,结合我的实验数据(附数据),撰写 300 字对比分析段落”。这种方法能让 AI 生成内容更贴近真实研究逻辑,同时通过手动补充实验细节形成 “AI 生成 + 人工验证” 的混合结构。
1. 结构重组法
使用 “对比式提示词” 替代直接生成,例如 “请对比 A 学者和 B 学者在 XX 问题上的研究方法差异,结合我的实验数据(附数据),撰写 300 字对比分析段落”。这种方法能让 AI 生成内容更贴近真实研究逻辑,同时通过手动补充实验细节形成 “AI 生成 + 人工验证” 的混合结构。
2. 语义干扰术
在保持原意的前提下,对句子进行 “语法变形”。比如将 “基于深度学习的图像识别方法” 改为 “通过深度神经网络实现图像特征的自动化提取”,同时加入 “在实际应用中发现该方法在复杂光照条件下存在鲁棒性不足的问题”。这种改写既改变了表达方式,又增加了真实研究中的问题发现过程。
在保持原意的前提下,对句子进行 “语法变形”。比如将 “基于深度学习的图像识别方法” 改为 “通过深度神经网络实现图像特征的自动化提取”,同时加入 “在实际应用中发现该方法在复杂光照条件下存在鲁棒性不足的问题”。这种改写既改变了表达方式,又增加了真实研究中的问题发现过程。
3. 引用熔断机制
每写 2 段就插入 3 处 2019 年后的最新文献引用,要求标注具体页码。例如在讨论研究方法时,引用 “Smith et al. (2023) 在《Nature》中提出的改进算法,其在处理多模态数据时的准确率提升了 12%”,通过高频次的学术引用打乱 AI 生成内容的连贯性。
每写 2 段就插入 3 处 2019 年后的最新文献引用,要求标注具体页码。例如在讨论研究方法时,引用 “Smith et al. (2023) 在《Nature》中提出的改进算法,其在处理多模态数据时的准确率提升了 12%”,通过高频次的学术引用打乱 AI 生成内容的连贯性。
4. 句式杂糅技巧
混合使用主动语态与被动语态、直接引语与间接引语。例如 “研究团队发现该现象与预期结果存在差异”(主动语态)可改写为 “该现象被观察到与预期结果存在显著差异,这一发现与 Jones (2022) 的研究结论一致”(被动语态 + 引用)。通过句式多样性降低 AI 生成内容的机械感。
混合使用主动语态与被动语态、直接引语与间接引语。例如 “研究团队发现该现象与预期结果存在差异”(主动语态)可改写为 “该现象被观察到与预期结果存在显著差异,这一发现与 Jones (2022) 的研究结论一致”(被动语态 + 引用)。通过句式多样性降低 AI 生成内容的机械感。
5. 模糊修饰策略
避免使用过于精确的表述,例如将 “准确率提升了 25%” 改为 “在多数测试场景下,准确率呈现出约 20%-30% 的提升趋势”。这种模糊化处理既符合学术写作的严谨性,又能规避检测系统对 “精确数值” 的敏感识别。
避免使用过于精确的表述,例如将 “准确率提升了 25%” 改为 “在多数测试场景下,准确率呈现出约 20%-30% 的提升趋势”。这种模糊化处理既符合学术写作的严谨性,又能规避检测系统对 “精确数值” 的敏感识别。
🧩 提升原创性的实战技巧
1. 研究过程具象化
在论文中加入实验失败记录、方案调整细节等 “人性化描述”。例如 “在第 3 次实验中,由于传感器校准误差导致数据异常,后续通过引入双传感器交叉验证方案解决了这一问题”。这些真实的研究过程细节是检测系统难以模拟的天然屏障。
1. 研究过程具象化
在论文中加入实验失败记录、方案调整细节等 “人性化描述”。例如 “在第 3 次实验中,由于传感器校准误差导致数据异常,后续通过引入双传感器交叉验证方案解决了这一问题”。这些真实的研究过程细节是检测系统难以模拟的天然屏障。
2. 跨学科融合创新
采用 “技术盲区 + 场景突破” 的选题公式,例如 “新能源车电池热管理系统的三维矩阵分析”。通过细分领域的创新选题,确保研究内容在现有数据库中缺乏直接比对对象,从源头降低重复率。
采用 “技术盲区 + 场景突破” 的选题公式,例如 “新能源车电池热管理系统的三维矩阵分析”。通过细分领域的创新选题,确保研究内容在现有数据库中缺乏直接比对对象,从源头降低重复率。
3. 人工润色黄金比例
将 AI 生成内容控制在 30% 以内,重点章节(如结论、创新点)必须手动撰写。例如 AI 生成文献综述后,手动补充 “近 2 年新增的学术争议焦点”,通过人工深度分析提升内容的原创性。
将 AI 生成内容控制在 30% 以内,重点章节(如结论、创新点)必须手动撰写。例如 AI 生成文献综述后,手动补充 “近 2 年新增的学术争议焦点”,通过人工深度分析提升内容的原创性。
4. 多工具协同验证
使用 DeepSeek 生成初稿,ChatGPT 进行逻辑优化,Quillbot 进行同义改写,最后通过 Zotero 进行文献管理。这种工具组合既能提升效率,又能通过多轮人工干预打破单一 AI 模型的语言模式。
使用 DeepSeek 生成初稿,ChatGPT 进行逻辑优化,Quillbot 进行同义改写,最后通过 Zotero 进行文献管理。这种工具组合既能提升效率,又能通过多轮人工干预打破单一 AI 模型的语言模式。
📚 引用与参考文献的避坑指南
1. 文献类型多元化
除了期刊论文,增加专利、行业报告、会议论文等非传统文献类型。例如在讨论技术应用时,引用 “国家知识产权局 2024 年公开的专利《一种基于区块链的供应链溯源系统》”,通过新颖的文献类型降低数据库比对概率。
1. 文献类型多元化
除了期刊论文,增加专利、行业报告、会议论文等非传统文献类型。例如在讨论技术应用时,引用 “国家知识产权局 2024 年公开的专利《一种基于区块链的供应链溯源系统》”,通过新颖的文献类型降低数据库比对概率。
2. 引用方式创新
采用 “观点冲突法” 构建文献综述,例如 “现有研究主要分为两大流派:一派认为 XX(Smith, 2022),另一派则强调 XX(Li, 2023),而本研究在融合两者的基础上提出了新的分析框架”。通过学术争议的梳理展现独立思考,避免简单罗列文献。
采用 “观点冲突法” 构建文献综述,例如 “现有研究主要分为两大流派:一派认为 XX(Smith, 2022),另一派则强调 XX(Li, 2023),而本研究在融合两者的基础上提出了新的分析框架”。通过学术争议的梳理展现独立思考,避免简单罗列文献。
3. 引用格式精细化
严格遵循目标高校的引用规范,例如 APA 格式中作者名的缩写规则、MLA 格式中页码标注的位置。同时注意引用内容的 “碎片化处理”,避免大段直接引用,可将引用内容拆解为 “研究背景→核心观点→局限性” 的三段式结构。
严格遵循目标高校的引用规范,例如 APA 格式中作者名的缩写规则、MLA 格式中页码标注的位置。同时注意引用内容的 “碎片化处理”,避免大段直接引用,可将引用内容拆解为 “研究背景→核心观点→局限性” 的三段式结构。
4. 文献时效性管理
确保 80% 以上的参考文献为近 3 年发表,特别是 2023-2025 年的最新研究。例如在讨论 AI 检测技术时,引用 “Wang et al. (2025) 提出的基于 Transformer 的上下文感知检测模型”,通过最新文献体现研究的前沿性。
确保 80% 以上的参考文献为近 3 年发表,特别是 2023-2025 年的最新研究。例如在讨论 AI 检测技术时,引用 “Wang et al. (2025) 提出的基于 Transformer 的上下文感知检测模型”,通过最新文献体现研究的前沿性。
⚡ 终极防检测组合策略
1. 写作过程留痕
使用支持版本控制的文档工具(如 Google Docs),保留从初稿到终稿的所有修改记录。必要时录制写作过程视频,展示从选题构思到数据处理的完整流程。这些证据可在遭遇误判时自证清白。
1. 写作过程留痕
使用支持版本控制的文档工具(如 Google Docs),保留从初稿到终稿的所有修改记录。必要时录制写作过程视频,展示从选题构思到数据处理的完整流程。这些证据可在遭遇误判时自证清白。
2. 多系统交叉检测
在提交前使用掌桥科研、Turnitin、维普等多个平台进行预检测。例如先用掌桥科研进行 AIGC 率分析,再用 Turnitin 检测重复率,最后通过知网进行语义比对。通过多维度检测提前发现潜在风险点。
在提交前使用掌桥科研、Turnitin、维普等多个平台进行预检测。例如先用掌桥科研进行 AIGC 率分析,再用 Turnitin 检测重复率,最后通过知网进行语义比对。通过多维度检测提前发现潜在风险点。
3. 人机协作深度融合
采用 “AI 生成框架 + 人工填充内容” 的写作模式。例如让 AI 生成论文框架和数据图表,人工撰写核心分析和结论部分。这种协作模式既能提升效率,又能确保内容的原创性和学术深度。
采用 “AI 生成框架 + 人工填充内容” 的写作模式。例如让 AI 生成论文框架和数据图表,人工撰写核心分析和结论部分。这种协作模式既能提升效率,又能确保内容的原创性和学术深度。
4. 学术规范严格遵循
仔细研读目标高校的《毕业论文 AI 工具使用规范》,例如四川大学要求文科 AI 率≤20%、理工医科≤15%。在论文中明确标注 AI 生成内容的位置和比例,避免因规范疏漏导致的学术不端风险。
仔细研读目标高校的《毕业论文 AI 工具使用规范》,例如四川大学要求文科 AI 率≤20%、理工医科≤15%。在论文中明确标注 AI 生成内容的位置和比例,避免因规范疏漏导致的学术不端风险。
通过以上策略的综合运用,既能有效应对 2025 年 AI 检测系统的技术升级,又能确保论文的学术质量和原创性。记住,真正的学术价值源于独立思考和创新研究,AI 工具只是辅助手段,合理使用才能实现效率与质量的双赢。
该文章由diwuai.com第五 ai 创作,第五 AI - 高质量公众号、头条号等自媒体文章创作平台 | 降 AI 味 + AI 检测 + 全网热搜爆文库
🔗立即免费注册 开始体验工具箱 - 朱雀 AI 味降低到 0%- 降 AI 去 AI 味
🔗立即免费注册 开始体验工具箱 - 朱雀 AI 味降低到 0%- 降 AI 去 AI 味















