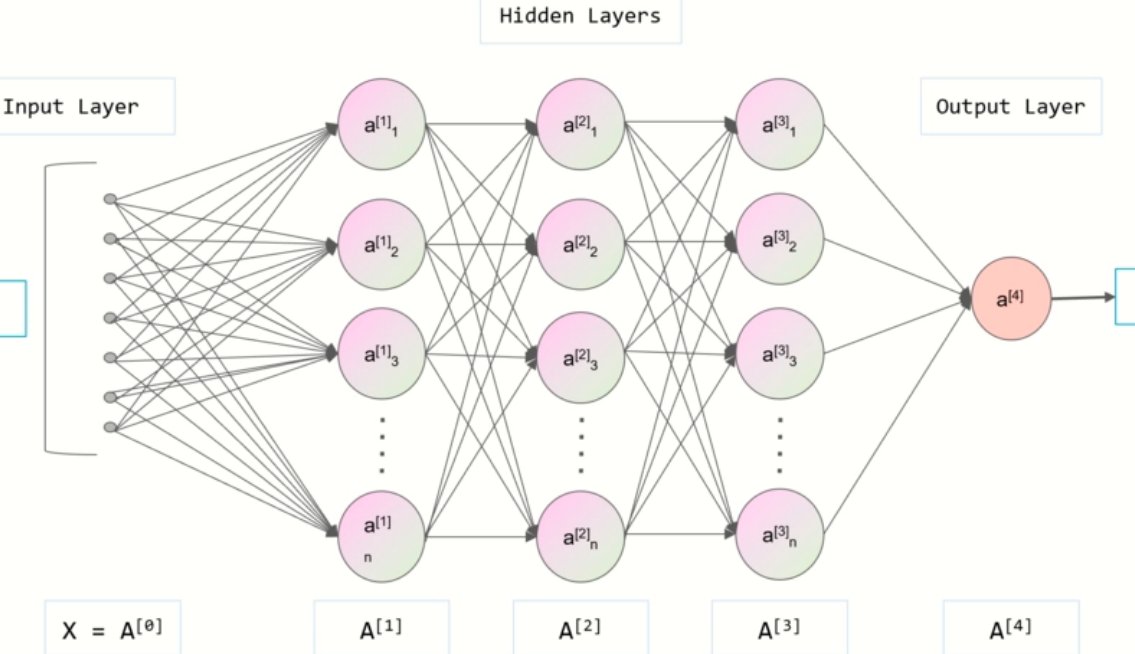
深度学习就像给机器打造了一套类似人脑的处理系统,多层神经网络像一层层过滤器,能从数据里提炼有用信息。要让机器写文章,第一步就是喂给它海量文本。可能是新闻、小说,也可能是各种专业论文。这些数据会被拆成小块,比如词语、短句,让神经网络慢慢琢磨。它会记住 “的” 后面常跟名词,“虽然” 之后可能有 “但是”,这些不起眼的规律,就是生成文章的基础。
🔍深度学习:文本生成的 “大脑” 架构
神经网络的层次越多,处理信息的能力就越强。早期的浅层网络只能处理简单的语言规律,比如把 “我吃饭” 改成 “饭被我吃”。现在的深度网络能处理更复杂的任务,比如根据一句话的开头,推测出合理的结尾。这就像人读书多了,看到开头就大概知道后面会讲什么。
训练过程其实是个不断纠错的过程。机器生成一句话后,会和真实的文本对比,看看差在哪儿。如果错了,就调整网络里的参数,下次尽量不犯同样的错。这个过程可能要重复几百万次,直到机器生成的内容越来越像人写的。
数据质量直接影响生成效果。如果喂给机器的都是错别字连篇的文本,那它写出来的东西也好不到哪儿去。所以技术团队会花大量时间清洗数据,去掉重复的、错误的内容,只留下高质量的文本。这一步很关键,就像人要读好书才能写出好文章一样。
分布式表示是深度学习的一大亮点。它能把词语转换成数字向量,让机器明白词语之间的关系。比如 “国王” 减去 “男人” 加上 “女人”,结果会接近 “女王” 的向量。这样机器就能理解词语的深层含义,而不只是表面的字符组合。
📝自然语言处理:让机器 “读懂” 人类语言
词嵌入技术是自然语言处理的基础。它把每个词变成一串数字,这些数字不是随便编的,而是根据词语在文本中的使用场景算出来的。比如 “苹果” 和 “香蕉” 的数字串比较接近,因为它们都是水果,常出现在类似的句子里。
语义分析能让机器理解句子的意思。不只是简单的词语对应,还要明白上下文。比如 “他把手机放在桌子上,它很沉”,机器要知道 “它” 指的是 “手机” 而不是 “桌子”。这需要分析句子结构和词语之间的逻辑关系,就像人理解话里的潜台词一样。
语言生成不只是把词语堆在一起,还要符合语法和逻辑。机器会先确定要表达的意思,然后选择合适的词语,再按正确的顺序排列。比如写一篇介绍旅游景点的文章,机器会先想清楚要讲景点的位置、特色、玩法,再组织语言,让内容有条理。
情感识别让机器能模仿人的语气。如果要生成一篇赞美某个产品的文章,机器会用积极的词汇和句式;如果是批评,就会用消极的表达。这需要从训练数据中学习不同情感对应的语言特征,比如 “太棒了”“推荐” 是积极的,“糟糕”“失望” 是消极的。
🚀从 RNN 到 GPT:生成模型的进化之路
RNN(循环神经网络)是早期的生成模型,它能处理序列数据,适合文本生成。但它有个缺点,处理长文本时容易 “忘事”。比如写一篇几千字的文章,前面提到的细节,后面可能就衔接不上了。这就像人记不住很久以前说过的话,导致前后矛盾。
LSTM(长短期记忆网络)改进了 RNN 的不足,能记住更久的信息。它就像给机器装了个备忘录,重要的信息会被记下来,无关的就丢掉。这样生成的长文本会更连贯,比如写故事时,前面出现的角色,后面还能合理地继续出场。
Transformer 模型的出现是个大突破,它用注意力机制让机器能关注到文本中的重要部分。就像人读书时,会重点看关键句子一样,机器生成内容时,也会注意和上下文相关的信息。这让生成的内容更贴合主题,不容易跑题。
GPT 系列模型把 Transformer 的能力发挥到了极致。GPT - 3 有 1750 亿个参数,能处理的信息远超之前的模型。它能写代码、写诗、写论文,甚至能模仿不同作家的风格。这背后是海量的训练数据和强大的计算能力,训练一次可能要花上亿美元,可见技术成本有多高。
⚠️一键生成背后的技术难题
语义连贯性是个大挑战。有时候机器生成的句子单独看没问题,但连起来就不对劲。比如前面说 “今天天气很冷”,后面突然说 “我去游泳了”,这就不符合逻辑。这是因为机器对上下文的理解还不够深入,只能处理局部的关系,缺乏全局的把握。
原创性问题一直存在。机器生成的内容可能和训练数据里的文本很像,甚至出现抄袭的情况。虽然技术上有去重处理,但很难完全避免。就像人写东西时,难免会受读过的文章影响,机器也一样,只是它 “读过” 的东西太多了,更容易重复。
处理专业领域的内容时,机器常出错。比如写一篇医学论文,涉及到专业术语和复杂的病理知识,机器可能会乱用术语,得出错误的结论。这是因为专业数据相对较少,机器学习不够充分,对专业知识的理解不够透彻。
多语言生成的质量参差不齐。生成英语内容可能效果很好,但生成一些小语种内容时,就会出现语法错误或表达不自然的情况。这是因为不同语言的训练数据量不一样,语言结构也有差异,机器很难完美适配所有语言。
🔍技术落地的场景与边界
自媒体创作中,一键生成能帮作者节省时间。比如写公众号文章,机器可以先生成初稿,作者再修改润色,提高效率。但不能完全依赖机器,毕竟机器写不出有独特观点和深度思考的内容,人的创造力还是不可替代的。
客服回复用生成技术能提高响应速度。常见的问题,机器可以自动生成标准答案,快速回复用户。但遇到复杂的问题,还是需要人工处理。比如用户投诉特殊情况,机器可能理解不了,生成的回复会很生硬,反而让用户不满意。
教育领域里,机器能生成练习题和讲解内容。老师可以用它来出试卷,节省出题时间。但在个性化辅导方面,机器还做不到,因为每个学生的学习情况不一样,需要老师根据具体情况调整教学,这是机器难以模仿的。
法律和医疗等领域,生成技术的应用要非常谨慎。法律文书需要准确无误,一点差错可能导致严重后果;医疗诊断更是关系到生命健康。目前机器生成的内容只能作为参考,不能直接使用,必须经过专业人士的严格审核。
🔮技术迭代:未来文章生成会走向何方
更精准的语义理解是发展方向。未来的模型可能像人一样,能理解复杂的逻辑推理和抽象概念。比如生成一篇哲学文章,能准确表达深刻的思想,而不是表面的词语堆砌。这需要在模型架构和训练方法上有新的突破。
个性化生成会更成熟。机器能根据用户的写作风格、喜好生成专属内容。比如有的用户喜欢简洁的表达,有的喜欢华丽的辞藻,机器都能模仿。这就像有个专属的秘书,知道你的写作习惯,写出的东西和你自己写的很像。
多模态生成将成为可能,不只是生成文本,还能结合图片、视频等。比如生成一篇旅游攻略,不仅有文字描述,还能自动配上相关的景点图片和视频链接。这需要文本生成技术和其他领域的技术结合,难度不小,但应用前景广阔。
伦理和规范会越来越受重视。随着技术的发展,如何防止生成虚假信息、谣言等问题会更突出。可能会出台相关的法律法规,要求生成的内容必须标明来源,不能用于违法用途。技术团队也会在模型里加入伦理约束,让机器生成的内容更负责任。
【该文章由diwuai.com
第五 ai 创作,第五 AI - 高质量公众号、头条号等自媒体文章创作平台 | 降 AI 味 + AI 检测 + 全网热搜爆文库🔗立即免费注册 开始体验工具箱 - 朱雀 AI 味降低到 0%- 降 AI 去 AI 味】















