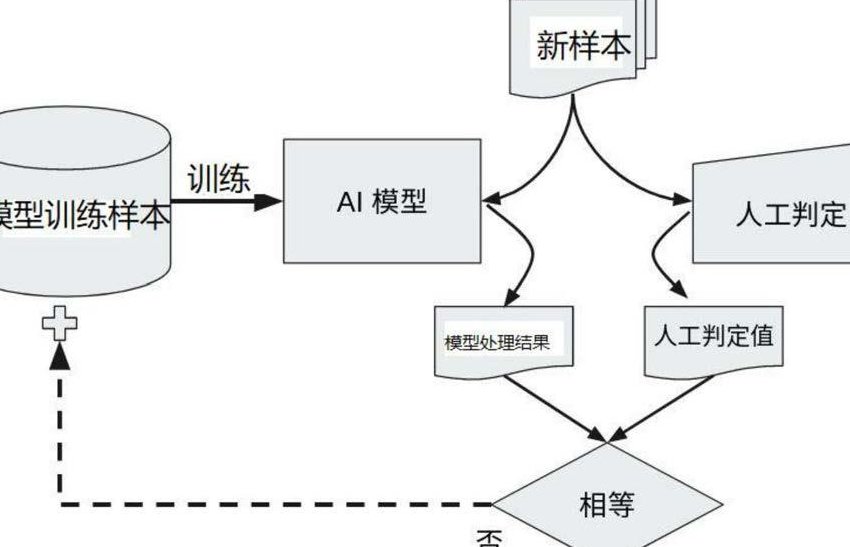
模型训练数据的质量直接决定了最终模型的性能。现在 AI 生成内容泛滥,很多看似可靠的数据源里可能混进了大量机器生成的内容。如果用这些数据训练模型,就像给植物浇了带杂质的水,长得好不好全看运气,甚至可能让模型学出错误的逻辑。所以学会筛选数据,尤其是过滤掉 AI 生成的部分,已经成了做模型训练的基础能力。
📌 数据筛选的三大基本原则
做数据筛选不能瞎筛,得有明确的原则打底。不然很容易陷入 “为了过滤而过滤” 的误区,把有用的真实数据也误删了。
真实性优先是第一准则。这里说的真实,不只是数据内容本身没错,更重要的是来源得可靠。比如从权威学术数据库爬的论文,和从不知名论坛扒的帖子,可信度肯定不一样。但也不能一刀切,有些小众平台可能有独特的真实用户内容,这时候就得结合其他维度判断。真实数据往往带着 “人的痕迹”,可能有语法小错误,可能有重复的口头禅,这些反而是真实性的证明。
时效性是容易被忽略的一点。尤其是做需要紧跟现实变化的模型,比如新闻推荐、市场分析类,老数据的价值会大打折扣。更麻烦的是,很多 AI 生成数据会模仿旧数据的风格,要是用了过期的真实数据做训练,生成的内容可能看起来很真,但早就跟不上当前的实际情况了。所以筛选时必须检查数据的时间戳,优先保留近 1 - 2 年内的内容,特殊领域比如科技、政策类,最好限定在 6 个月内。
关联性得和模型目标绑定。比如训练医疗问答模型,就得重点筛选医学论文、专业医患问答数据。要是混入大量无关的 AI 生成内容,比如随便写的生活随笔,就算是真实的,对模型提升也不大。筛选时可以用关键词匹配,但别只看表面,得深层分析内容和任务的相关性。比如 “糖尿病” 这个关键词,在食谱分享里出现,和在病理分析里出现,对医疗模型的价值完全不同。
🔍 AI 生成数据的四大识别方法
识别 AI 生成数据得像侦探破案,从多个角度找线索。现在的 AI 生成技术越来越厉害,单靠一个特征很难准确判断,得组合拳出击。
先看语言特征。AI 生成的内容往往有 “过度规范” 的问题。人类写作难免有重复的词、不那么通顺的句子,AI 却会刻意避免这些,导致文本看起来太 “完美”。比如词汇多样性异常高,很少用口语化的表达,或者句式结构特别规整,几乎没有长短句交错。可以用工具检测文本的 perplexity 值(困惑度),AI 生成内容的这个值通常比人类写的低,因为机器更 “确定” 自己要输出什么。另外,有些 AI 模型有固定的 “口头禅”,比如频繁用 “综上所述”“然而” 这类连接词,积累这些特征库能提高识别效率。
再看逻辑结构。人类写东西,逻辑可能有跳跃,会突然插入一个例子,或者绕个弯子再回到主题。AI 生成的内容逻辑太 “顺”,甚至顺得不合理。比如写一篇分析文章,会严格按照 “提出问题 - 分析原因 - 给出对策” 的模板来,缺少自然的思维波动。更明显的是,当涉及到专业知识时,AI 可能会编造看似合理但实际错误的内容,比如写历史事件时,时间线没错,但细节描述和真实情况有偏差,这种 “半真半假” 的内容最容易迷惑人。
跨源比对很关键。真实数据通常会在多个渠道有交叉验证,比如一个新闻事件,不同媒体报道的角度可能不同,但核心事实是一致的。AI 生成的内容,尤其是编造的信息,很难在其他可信来源找到印证。可以用数据里的关键信息点,比如人名、事件、数据,去权威数据库检索。如果多次检索都没有匹配结果,就得高度怀疑是 AI 生成的。另外,同一主题下的内容,如果表述方式高度相似,但来源不同,也可能是用同一套 AI 模板生成的。
看数据分布。真实数据的质量是有波动的,有写得好的,也有写得一般的。如果一批数据看起来质量都差不多,没有明显的高低差异,很可能是 AI 生成的。可以随机抽取样本,人工评估质量等级,计算方差。方差过小的数据集,就得重点排查。还有一种情况,某些特定话题的内容突然大量出现,和整体数据分布不符,这也可能是 AI 批量生成的结果。
🛡️ 高效过滤策略:从源头到终端的全流程控制
过滤 AI 生成数据不能只靠后期筛查,得从源头就开始控制。就像治水,堵不如疏,提前做好防范,能减少很多后续的麻烦。
数据源准入要严格。优先选择有明确审核机制的平台,比如学术期刊、正规媒体、经过认证的专业论坛。这些地方虽然也可能有 AI 生成内容,但比例相对低很多。对于用户生成内容(UGC)平台,比如微博、知乎,要限制爬取范围,只抓有实名认证、历史内容丰富的用户发布的内容。新注册账号、发布内容少、互动率低的用户,其内容要标记为高风险,重点审核。还有些专门的 AI 生成内容平台,比如某些 AI 写作工具的展示页,这类数据源直接排除。
预处理阶段做初步过滤。拿到原始数据后,先用规则库做第一轮清洗。比如设置关键词黑名单,包含某些 AI 生成工具特有的标记词。再用简单的 NLP 模型检测文本的流畅度异常值,把那些 “完美得不像人类写的” 内容筛出来。对于长文本,可以拆分成段落,检查段落间的逻辑连贯性,AI 生成的长文往往在段落过渡处有明显的生硬感。预处理时还要注意去重,很多 AI 生成内容会批量复制粘贴,重复率高的内容直接删除。
分场景制定过滤阈值。不同的模型对数据纯度的要求不一样。比如做通用聊天机器人,允许混入 5% 以内的 AI 生成数据,影响可能不大。但做医疗、法律这类高精准度要求的模型,这个比例得降到 1% 以下。过滤时可以设置动态阈值,根据数据稀缺程度调整。比如某个专业领域的数据特别少,稍微放宽点标准;数据充足的时候,就严格把关。阈值设定不能拍脑袋,得通过小范围测试,看混入不同比例的 AI 数据对模型性能的影响,找到平衡点。
人工复核不可少。机器过滤总有漏网之鱼,尤其是那些高级 AI 生成的内容,很接近人类水平。这时候就得靠人工抽检。可以随机抽取 10% - 20% 的过滤后数据,让专业人员判断是否有 AI 生成的痕迹。如果发现漏检率超过 3%,就得调整过滤规则。对于那些机器难以判断的 “灰色地带” 数据,全部交给人工审核。人工复核还能积累样本,用来优化机器过滤模型,形成正向循环。
✅ 数据真实性的多层验证机制
过滤掉 AI 生成数据后,还得验证剩下的数据是不是真的可靠。真实性验证是最后一道防线,不能马虎。
交叉验证是个好办法。把同一主题的不同来源数据放在一起比对,看核心信息是否一致。比如一篇关于经济数据的报道,既要看统计局发布的原始数据,也要看不同媒体的解读,还要参考专家的分析。如果只有单一来源的信息,没有其他佐证,就算不是 AI 生成的,可信度也得打个问号。对于学术类数据,要检查是否有引用文献,引用的文献是否真实存在,影响因子如何。交叉验证能有效避免 “以讹传讹” 的真实数据,也就是人类写的但内容错误的信息。
追溯数据来源的可信度。不只是看来源平台,还要看具体的发布者。比如一个科技博主,过去发布的内容是否有过不实信息,专业背景如何,在行业内的口碑怎么样。可以建立来源可信度评分体系,从平台权威性、发布者资质、历史记录等多个维度打分,分数低于阈值的内容直接排除。对于转载的内容,要找到最初的发布源头,不能只看二次转载的平台。有些 AI 生成内容会被多次转载,看起来好像有很多来源,其实源头就是机器生成的。
动态更新验证标准。AI 技术在进步,生成的内容越来越像人类写的,以前的验证方法可能慢慢失效。得定期更新验证规则,加入新发现的 AI 生成特征。比如某个新的 AI 模型擅长模仿特定领域的专家风格,就得针对性地调整识别策略。可以关注 AI 生成技术的最新进展,跟踪相关论文和报道,提前预判可能出现的新特征。同时,也要收集自己过滤过程中误判的案例,分析原因,不断优化验证机制。
用户反馈闭环很重要。模型上线后,用户的反馈能帮我们发现数据中的问题。比如用户指出某个回答内容错误,或者感觉 “不像人说的话”,就要追溯到训练数据里对应的来源,检查是不是漏网的 AI 生成内容,或者是真实但错误的数据。把这些案例加入到数据问题库,用来改进下一轮的筛选和验证流程。用户反馈还能帮我们发现某些特定场景下的数据缺陷,比如某个细分话题的真实数据不足,导致模型回答生硬,这时候就知道该重点补充这类数据了。
🔮 未来趋势:AI 对抗中的数据筛选新挑战
数据筛选这场仗只会越来越难打。AI 生成技术和数据过滤技术就像矛和盾,一直在互相升级。得提前做好准备,应对未来的挑战。
多模态数据的筛选会更复杂。现在已经不只是文本数据了,图片、视频、音频里都可能混入 AI 生成的内容。比如 AI 生成的假新闻图片,看起来和真实照片几乎一样。未来的筛选工具必须能处理多模态数据,从视觉、听觉等多个维度识别。这就需要跨领域的技术融合,把文本识别的经验用到图像、音频上,比如分析图片的光影是否自然,音频的语气是否有机器感。
主动防御比被动过滤更有效。与其等 AI 生成数据混进来再筛,不如主动构建高质量的真实数据源。比如和权威机构合作,获取独家的真实数据;或者设计激励机制,鼓励用户贡献高质量的原创内容。有些平台已经开始这么做了,给真实创作者发认证标识,优先推荐他们的内容,同时打上不可篡改的来源标记,方便后续的数据筛选。主动构建的数据源,不仅真实性有保障,和模型目标的关联性也更强。
行业标准的建立是当务之急。现在数据筛选全靠各自摸索,没有统一的标准,导致不同机构的模型训练数据质量参差不齐。需要行业内共同制定 AI 生成数据的识别标准、过滤流程、验证方法,甚至可以开发共享的 AI 生成特征库。这样小公司不用从零开始做筛选,大公司也能避免重复劳动。标准的建立还能提高整个行业的透明度,让用户更信任 AI 模型的输出结果。
说到底,保证数据源的真实性,不只是技术问题,更是态度问题。宁愿用少量高质量的真实数据,也不要为了数量混入可疑内容。模型训练就像盖房子,数据是地基,地基不牢,房子再漂亮也站不住。过滤 AI 生成数据,不是和 AI 作对,而是为了让 AI 更好地服务人类,毕竟我们需要的是能理解真实世界、解决真实问题的人工智能。
【该文章由diwuai.com
第五 ai 创作,第五 AI - 高质量公众号、头条号等自媒体文章创作平台 | 降 AI 味 + AI 检测 + 全网热搜爆文库🔗立即免费注册 开始体验工具箱 - 朱雀 AI 味降低到 0%- 降 AI 去 AI 味】















