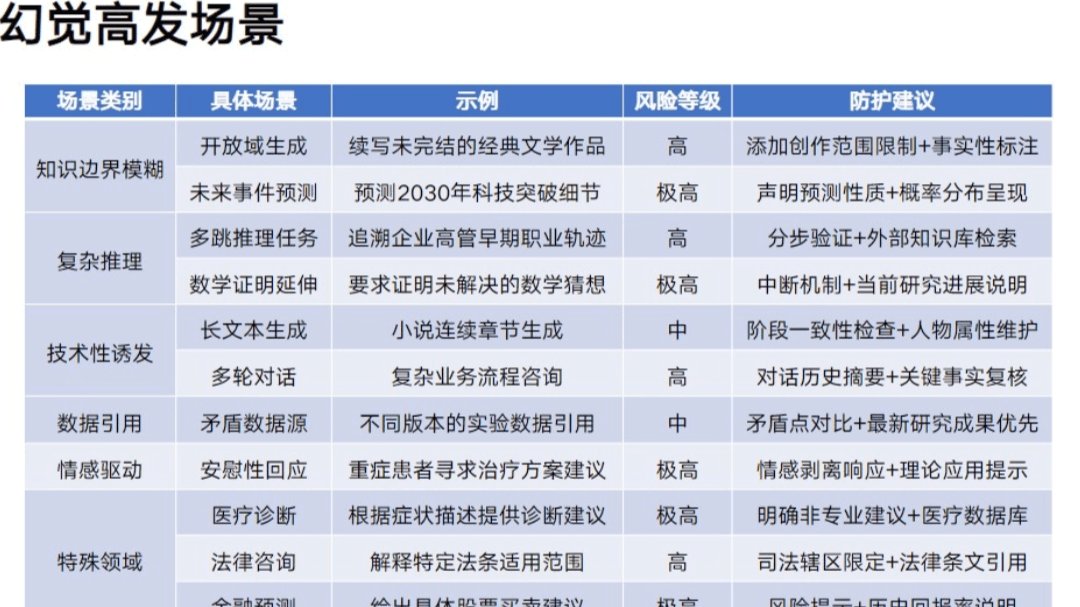
现在做学术的,谁还没试过用 AI 搜论文?但说真的,这东西用不好就坑人 ——AI 生成的论文内容看着头头是道,引用格式规范,数据还带小数点,结果你拿去用才发现,参考文献是编的,实验数据对不上,甚至连核心观点都是 “无中生有”。这就是 AI 搜索论文最让人头疼的 “幻觉现象”。今天就跟大家掰扯掰扯这里面的坑,再给几个能落地的避坑技巧。
🚨 先搞懂:AI 搜索论文的 “幻觉” 到底有多坑?
你可能遇到过这种情况:让 AI 搜一篇关于 “碳中和政策对新能源产业影响” 的论文,它很快给你列了 5 篇参考文献,作者、期刊、发表时间都清清楚楚,甚至还摘了一段原文。你觉得省事,直接拿来当论据,结果导师一查 —— 其中 3 篇期刊根本没发表过这篇文章,还有 1 个作者名字都是错的。这就是典型的 AI 幻觉。
AI 生成内容的逻辑是 “预测下一个词”,不是 “还原事实”。它会根据训练数据里的规律,生成看起来合理的内容,但如果训练数据里有冲突信息,或者它对某个领域的知识储备不足,就容易 “编故事”。尤其在论文搜索里,“看起来对” 和 “实际对” 完全是两码事。
更坑的是,有些幻觉不是硬错,是 “软错”。比如 AI 引用了一篇真实存在的论文,但把核心结论改了一点点 —— 原文说 “某技术能提升效率 15%”,它写成 “25%”。这种错误特别难发现,除非你逐字核对原文。我见过有学生因为这个,整个论文的数据分析都错了,返工花了一个月。
还有一种情况,AI 会 “捏造” 权威来源。比如你搜医学类论文,它可能会编一个 “某权威医学期刊 2024 年最新研究”,但实际上这期刊当年根本没发过相关主题。新手很容易被 “权威感” 骗到,觉得 AI 总不会乱编期刊名吧?还真会。
🚫 这些 “想当然” 的操作,正在让你掉进幻觉陷阱
很多人用 AI 搜论文,都有几个默认的 “省心操作”,但这些操作恰恰是幻觉的温床。
最常见的就是 **“直接要结果,不问过程”**。比如直接让 AI“搜 10 篇关于人工智能在教育领域应用的核心论文,并总结观点”。这种指令下,AI 为了满足 “10 篇” 的数量要求,很可能凑数 —— 把相似主题的论文改头换面,甚至凭空生成。你要是换成 “搜近 3 年 CSSCI 期刊中,人工智能在教育领域应用的论文,列出具体标题、作者及发表时间,并说明你是如何筛选的”,AI 编造的概率会低很多。
另一个误区是 **“不看 AI 的‘知识截止时间’”**。比如现在是 2025 年,你让 AI 搜 “2024 年某领域最新论文”,但如果这 AI 的知识只更新到 2023 年,它就只能基于旧数据 “推测” 2024 年的内容,这时候出现幻觉是必然的。每次用 AI 前,先确认它的知识截止时间,超过这个时间的内容,必须自己交叉验证。
还有人觉得 “AI 给的引用格式对,内容就对”。大错特错!AI 对格式的掌握远好于对事实的掌握。它能完美生成 APA、MLA 格式的引用,但里面的内容可能全是编的。我见过最离谱的案例:AI 生成的引用格式规范到标点都没错,但点进期刊官网一查,那期杂志根本不存在。
✅ 避开幻觉的核心逻辑:把 AI 当 “助手”,不是 “专家”
想让 AI 搜论文不踩坑,关键是改变使用逻辑 ——AI 适合帮你 “找方向、筛信息”,但不能让它 “做决策、给结论”。
第一步,用 AI 缩小范围,不用它定结论。比如你想研究 “元宇宙在文化遗产保护中的应用”,可以先让 AI “列出这个领域的 3 个核心研究方向和 5 个关键词”,这时候它不容易出错。拿到方向后,自己去知网、Web of Science 搜这些关键词,找到真实论文。AI 给的方向可能有偏差,但总比你盲目搜强,这一步能省不少时间。
第二步,所有 AI 给的 “具体信息”,必须 “双源验证”。什么是具体信息?比如作者、期刊名、发表时间、数据、实验结论。验证方法很简单:先去论文数据库(知网、PubMed、IEEE Xplore 等)搜标题或作者,看能不能找到原文;再去期刊官网查该期目录,确认论文是否真的发表过。如果 AI 说 “某论文发表在《中国社会科学》2024 年第 3 期”,你就去《中国社会科学》官网,找到 2024 年第 3 期的目录,逐篇核对。
这里有个技巧:如果 AI 给的论文标题很长,你可以截取核心关键词搜索。比如标题是 “基于深度学习的城市交通流量预测模型优化研究 —— 以北京市为例”,搜 “深度学习 城市交通流量预测 北京” 会比全标题搜更高效。
🛠️ 3 个能落地的实操技巧,亲测有效
分享几个我自己用了半年的方法,能把 AI 幻觉概率降到最低。
第一个,给 AI 加 “约束条件”,逼它 “说真话”。比如不要说 “搜相关论文”,要说 “搜近 5 年被 SCI 收录的论文,只列有明确 DOI 号的,如果你不确定是否存在,就标注‘待验证’”。DOI 号是论文的唯一标识,就像身份证号,AI 很难编造有效的 DOI。如果它列不出 DOI,或者标注了 “待验证”,你就知道这部分要重点核对。
我试过用这个方法,之前 AI 给我列了 8 篇论文,其中 2 篇没 DOI,后来发现这 2 篇果然是编的。有 DOI 的 6 篇,全部能在 Crossref(DOI 数据库)里查到。
第二个,用 “反向提问” 验证 AI 的确定性。比如 AI 说 “某论文提出 XX 观点”,你接着问:“这个观点在论文的第几章第几节?原文大概是什么表述?” 如果它支支吾吾,说 “无法确定具体位置”,那这个观点很可能有问题。真正存在的论文,AI 如果有相关数据,至少能说出大致章节(比如 “引言部分”“实验结果分析部分”)。
第三个,把 AI 生成的内容 “拆碎了查”。比如 AI 总结某篇论文 “用了 A 方法,得到 B 结论,数据支持 C 观点”,你不要整体信,而是分别查:A 方法是否真的被该论文使用?B 结论有没有原文支撑?C 观点的数据来源是什么?拆得越细,越容易发现漏洞。
举个例子,之前 AI 说 “某篇经济学论文用了双重差分法,证明了减税对中小企业投资的促进作用”,我先查这篇论文是否用了双重差分法(去原文方法部分看),再查结论是否提到 “促进作用”(看讨论部分),最后核对数据表格里的显著性水平 —— 果然,AI 把 “不显著” 说成了 “显著”。
📌 最后提醒:这 3 类论文,最好别让 AI 搜
不是所有论文都适合用 AI 搜,这几类尤其要注意,AI 幻觉概率极高。
第一类:冷门领域或最新研究。比如 “古文字数字化修复” 这种小众领域,AI 训练数据少,很容易编内容。还有 2024-2025 年刚发表的论文,AI 可能还没收录,大概率靠猜。
第二类:需要精确数据的论文。比如医学论文里的 “生存率”“副作用发生率”,经济学论文里的 “GDP 增长率”“失业率”。这些数据差一点就会影响结论,AI 对数字的 “编造欲” 特别强。
第三类:非英语的外文论文。比如日文、德文的小众论文,AI 的训练数据主要是英文和中文,对小语种论文的识别准确率低,很容易把作者名、期刊名译错,甚至编一篇出来。
说到底,AI 是个好工具,但用在论文搜索上,必须带着 “怀疑心”。记住:AI 给的永远是 “线索”,不是 “证据”。线索需要你自己去验证,才能变成能用的证据。别图省事,学术里的 “省事”,最后往往要花更多时间弥补。
【该文章由diwuai.com第五 ai 创作,第五 AI - 高质量公众号、头条号等自媒体文章创作平台 | 降 AI 味 + AI 检测 + 全网热搜爆文库
🔗立即免费注册 开始体验工具箱 - 朱雀 AI 味降低到 0%- 降 AI 去 AI 味】
🔗立即免费注册 开始体验工具箱 - 朱雀 AI 味降低到 0%- 降 AI 去 AI 味】















