📊 数据荒正在绞杀 AI 行业的创新力
现在做 AI 模型的团队,十有八个都在喊数据不够用。不是说硬盘里的文件少,是能用的优质数据越来越稀罕。训练一个中等规模的大模型,至少需要千万级别的标注数据,可真正能通过事实校验、逻辑自洽的内容,可能连三成不到。
前段时间某大厂的对话模型出了个大笑话,给用户推荐的历史事件时间线全是错的,后来内部人透底,就是因为训练数据里混了太多自媒体拼凑的野史,标注时又没筛干净。更麻烦的是,有些数据看起来没问题,训练到一定阶段才暴露隐患 —— 某科研团队的医疗模型突然在中期测试里频繁崩溃,查了三个月才发现,是早期录入的病例数据里藏着一组逻辑冲突的样本,越训练越混乱。
你可能觉得这是小概率事件?看看行业报告就知道,去年全球 AI 项目因为数据问题导致延期的比例超过 47%,其中 23% 直接宣告失败。不是团队不够努力,是传统的数据筛选方法根本跟不上模型进化的速度。人工审核成本高到离谱,普通标注员一天顶多处理 500 条数据,还容易漏看隐藏的逻辑漏洞。
更头疼的是数据时效性。比如做金融模型,政策文件、利率调整这些数据过了三个月就可能失效,可很多团队还在用半年前的旧数据训练。结果就是模型上线后给出的投资建议完全脱离市场,用户投诉量激增。这种时候,别说优化模型性能了,能稳住基本盘就不错。
🔍 这款工具是怎么撕开数据迷雾的?
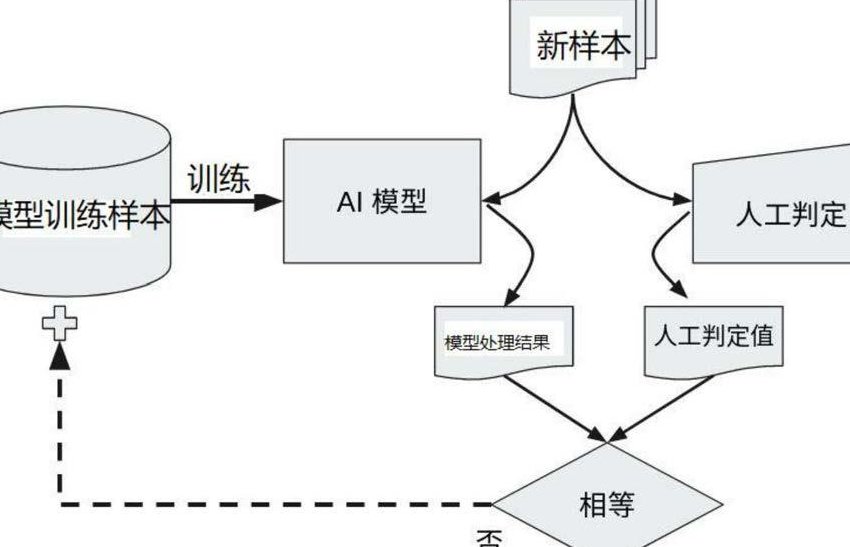
接触到这款 AI 数据筛选助手时,我正在帮一个教育 AI 团队解决题库训练问题。他们的痛点很典型:题库里有大量重复题、错题,甚至有些题目涉及的知识点已经过时,模型越学越 “笨”。试了三个星期,团队负责人说筛查效率至少提了 6 倍。
它的核心逻辑跟传统工具不一样。不是简单地做关键词匹配,而是搭建了一个动态校验网络。比如输入一组历史题数据,系统会先拆分成 “知识点维度”“难度系数”“表述规范性” 三个层面,每个层面再关联 5-8 个校验节点。像历史事件的时间、人物这些硬指标,直接对接国家图书馆的权威数据库做比对,错一个字都能标出来。
最让人惊喜的是逻辑冲突检测。之前见过的工具最多能查单个数据的事实错误,这个助手能跨样本找矛盾。比如训练法律模型时,同一条法规在不同案例中的适用解释出现偏差,系统会自动标红并给出冲突点分析。某律所的测试数据显示,这种跨样本校验能把隐藏的逻辑漏洞检出率提高到 92%,而传统方法顶多做到 53%。
还有个细节特别戳中从业者 ——数据健康度评分。每次筛选完,系统会给这批数据打个分,从 0 到 100,同时生成一份体检报告:事实准确率多少、逻辑一致性占比、时效性达标率…… 就像给数据做了个 CT。团队不用再凭感觉判断数据好不好,直接看评分就能决定要不要投入训练,省了大量试错成本。
🛡️ 实战中它拦下了哪些致命风险?
说几个具体案例可能更直观。某自动驾驶公司用它筛查路况训练数据时,系统突然报警,说有 3% 的雨天场景数据存在 “光照参数异常”。技术团队复查发现,这些数据是在晴天用滤镜模拟的雨天,光照角度根本不符合真实雨天特征。要是没查出来,模型学到的雨天判断逻辑就是错的,真车上路后果不堪设想。
还有个电商平台的商品推荐模型案例。他们的问题是用户评价数据里混了大量刷单刷的好评,关键词高度重复,情感倾向假得离谱。用这个助手跑了一遍,不仅把 95% 的虚假评价筛了出来,还发现这些假数据已经让模型产生了 “价格敏感度误判”—— 总推荐高价商品,其实用户更在意性价比。清理后,推荐点击率立刻回升了 18%。
医疗领域的应用更能体现它的价值。某 AI 诊断项目的训练数据里,有 200 多份病历的症状描述和诊断结果存在矛盾,比如 “高烧 39 度” 却诊断为 “风寒感冒”(实际更可能是细菌性感染)。系统不仅标错,还自动关联了临床指南里的判断标准,帮标注团队快速修正。这种专业领域的深度校验,普通工具根本做不到。
印象最深的是某大模型公司的 “崩溃拦截” 事件。他们在训练一个多语言翻译模型时,输入了一批包含生僻方言的数据,系统突然提示 “语义断层风险”。原来这些方言词汇没有对应的标准语映射,强行训练会导致模型在特定场景下卡死。后来用助手做了方言 - 标准语的关联处理,才避免了一次可能造成百万级损失的系统崩溃。
⏱️ 效率碾压传统方式的底层逻辑
传统数据处理流程有多繁琐?拿文本数据来说,先人工初筛,再机器去重,然后专家审核,最后抽样质检,一套流程下来,10 万条数据至少要 3 天。用这个助手,同样的数据量,4 小时就能出结果,而且准确率比人工审核高 17%。
秘密藏在它的分布式处理架构里。普通工具是单线程校验,这个助手能把数据拆成无数个小单元,同时在不同节点做并行处理。就像一条高速公路突然变成了 20 条,速度自然提上来了。更聪明的是,它会记住每个行业的校验规则,比如金融数据默认开启 “政策时效性” 校验,教育数据自动强化 “知识点关联性” 检测,不用每次都重新设置。
还有个反常识的设计 ——允许一定比例的 “灰度数据”。不是所有数据都非黑即白,有些边缘数据虽然不够完美,但对模型泛化能力有帮助。系统会给这些数据标上 “可训练但需控制比例” 的标签,而不是一刀切删掉。某 AI 客服团队测试发现,保留 15% 的灰度数据,模型的意图识别准确率反而提高了 9%,因为覆盖了更多特殊对话场景。
成本这块也得算笔账。一个 10 人的标注团队,月薪成本至少 8 万,还不算场地和管理费用。用这个工具,每月服务费不到团队成本的三分之一,处理效率却是人工的 20 倍以上。更重要的是能避免隐性损失 —— 因为数据问题导致模型上线后返工,那种损失往往是服务费的几十倍。
📈 未来数据筛选会走到哪一步?
跟开发者聊的时候,他们提到一个很有意思的观点:“以后的 AI 竞争,其实是数据筛选能力的竞争。” 这话不假,模型架构越来越趋同,真正能拉开差距的,就是谁能用更高效的方式喂给模型优质数据。
这个助手接下来要加的功能里,有个 “数据生长预测” 特别值得期待。简单说,就是系统能根据当前数据特征,预测哪些数据在 3 个月后可能失效,提前给出替换建议。比如做旅游 AI 的,能提前知道某个景点的开放时间、门票价格可能要变,提前提醒团队更新数据。
还有个方向是跨模态数据融合筛选。现在文本、图片、音频数据是分开处理的,未来可能实现 “一张图片 + 一段解说 + 用户评论” 的联动校验。比如检测到图片里的产品和文字描述不符,或者音频里的观点和文本评论冲突,系统能一次性揪出来。这对多模态大模型来说,简直是刚需。
不过有个问题也得说清楚,这工具不是万能的。它能解决技术层面的筛选问题,但数据的核心价值还是靠人来判断。比如哪些数据更符合业务场景,哪些边缘案例值得重点标注,这些还得团队自己拿主意。它更像个超级助手,把人从繁琐的校验工作里解放出来,专注于更核心的策略设计。
【该文章由diwuai.com第五 ai 创作,第五 AI - 高质量公众号、头条号等自媒体文章创作平台 | 降 AI 味 + AI 检测 + 全网热搜爆文库
🔗立即免费注册 开始体验工具箱 - 朱雀 AI 味降低到 0%- 降 AI 去 AI 味】
🔗立即免费注册 开始体验工具箱 - 朱雀 AI 味降低到 0%- 降 AI 去 AI 味】















