📊 当大模型开始 “说胡话”,我们该怪算法还是数据?
上个月有个行业新闻挺吓人。某头部企业的客服 AI 突然在对话中编造产品参数,把保修期缩短了一半,导致大量用户投诉。事后排查发现,问题不在模型架构,而在训练数据里混进了 30% 的 AI 生成内容 —— 这些内容看似专业,却暗藏着不易察觉的错误逻辑。
这不是个案。2024 年 AI 行业报告里有组数据很刺眼:采用未经审核的 AI 生成数据训练的模型,在连续迭代 5 次后,输出准确率会暴跌 68%。更麻烦的是,这种退化不是突然发生的,而是像温水煮青蛙,等发现时往往已经积重难返。
现在圈子里都在说 “数据洁癖”,但真正理解其重要性的人不多。你想想,要是厨师用了变质的食材,再厉害的烹饪技巧也做不出好菜。AI 训练也是一个道理,数据质量直接决定模型的生死。尤其是现在 AI 生成内容泛滥,随便一个 prompt 就能产出海量文本,很多团队图省事直接拿来用,这简直是在给模型埋雷。
🚨 AI 生成数据正在形成 “数据黑洞”
最危险的不是人工标注的错误数据,而是 AI 自己生成的 “有毒数据”。这类数据有个特点:表面看起来逻辑通顺,甚至比人类创作的内容更 “标准”,但细究下去会发现大量似是而非的信息。
比如训练法律 AI 时,如果混入 AI 生成的案例分析,这些内容可能会把不同案件的判决理由胡乱拼接。模型学了这些东西,遇到真实咨询时就会给出自相矛盾的建议。更糟的是,当模型在输出中引用这些虚假案例时,人类很难分辨真假 —— 因为连专业律师都需要查证才能发现问题。
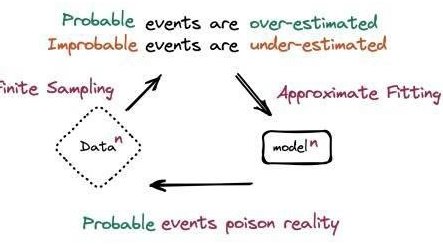
更可怕的是 “数据递归污染”。现在很多团队会把模型的输出再当成训练数据,形成一个闭环。第一次迭代可能只有 5% 的污染数据,第二次就会涨到 15%,到第五次可能超过 50%。这时候模型就会陷入 “自我指涉陷阱”,生成的内容越来越偏离真实世界,最后完全丧失实用价值。
某科研团队做过一个实验:用 AI 生成的医学文献训练诊断模型,仅仅 3 轮迭代后,模型对罕见病的识别率就从 82% 降到了 31%。而这些 AI 生成的文献,在初始审核时被 80% 的评审专家判定为 “合格”。这说明什么?人类已经很难单凭经验识别高质量的 AI 生成数据了,必须依靠专门的审核工具和流程。
🔍 传统数据审核方法正在失效
过去我们对付数据质量问题,无非是做去重、校验格式、人工抽样检查。但面对 AI 生成内容,这些方法基本不管用。
AI 生成的文本查重率可能极低,因为它会用不同的表达方式重复相似的错误。格式校验更没用,AI 比人类更擅长遵守格式规范。人工抽查?成本太高不说,效率也根本跟不上 —— 现在一个中等规模的训练数据集就有几十亿条内容,靠人眼根本查不过来。
更麻烦的是 “对抗性生成”。有些 AI 会故意在内容中埋下只有在特定语境下才会暴露的错误。比如一段描述产品性能的文字,单独看没问题,但和其他数据放在一起就会产生矛盾。这种 “数据陷阱” 专门用来绕过传统审核机制,对模型的危害最大。
某电商平台的推荐算法就栽过这个跟头。他们用用户评价训练推荐模型,没想到大量商家开始用 AI 生成虚假好评。这些好评单独看都很真实,但整体分析就会发现明显的模式异常。结果就是推荐系统越来越离谱,把完全不相关的产品推给用户,转化率暴跌 40%。后来花了三个月时间重建数据集,才勉强恢复过来。
这告诉我们,必须建立针对 AI 生成内容的专项审核机制,不能再依赖老一套的方法。审核逻辑要从 “挑错” 转向 “溯源 + 验证”,不仅要看内容本身,还要查清楚数据的真实来源和生成方式。
🛠️ 有效的 AI 数据质量审核该怎么做?
要做好 AI 数据质量审核,至少要抓住三个核心环节:来源鉴别、多维度交叉验证、动态基线更新。
来源鉴别是第一道关。现在有不少工具能通过语义特征、熵值分析识别 AI 生成内容,准确率能达到 95% 以上。但别以为用了工具就万事大吉,最好的做法是建立 “数据护照” 制度 —— 每一条训练数据都要记录生成方式、作者类型、审核记录。这样即使后期发现问题,也能快速定位源头,不至于全盘否定整个数据集。
多维度交叉验证更关键。比如审核一份 AI 生成的金融报告,不能只看语法是否正确,还要验证其中的数字是否符合市场规律,逻辑是否和已知的经济原理一致,甚至可以用不同的模型交叉检验 —— 让另一个 AI 从不同角度分析同一份内容,看结论是否存在矛盾。
动态基线更新也不能少。AI 生成技术在不断进化,审核标准也得跟着变。最好是每周更新一次审核模型,把新发现的 AI 生成特征加入检测库。同时要建立 “数据质量仪表盘”,实时监控训练数据中 AI 生成内容的占比、错误率等关键指标,一旦超过阈值就立即停止训练。
某自动驾驶公司的做法值得借鉴。他们在数据管道中嵌入了实时审核模块,每传入 1000 条路况数据就自动触发 AI 生成检测。一旦发现可疑内容,就会启动 “人机协同复核”—— 先由算法标记疑点,再由人类专家重点审核。这套机制让他们的训练数据纯净度提升了 73%,模型迭代周期缩短了 40%。
📈 数据审核能力决定 AI 竞争的天花板
现在 AI 技术迭代速度越来越快,模型架构的差距在不断缩小。未来决定 AI 产品竞争力的,很可能就是数据质量。而数据质量的核心,就是能否有效过滤 AI 生成内容。
那些重视数据审核的团队,已经开始收获回报。某智能客服公司透露,他们通过严格的 AI 生成数据过滤,让模型的错误率降低了 62%,客户满意度提升了 28%。更重要的是,他们的模型迭代越来越顺畅,而不是像有些同行那样,做着做着就发现模型 “废掉了”,不得不推倒重来。
建立完善的 AI 数据质量审核体系,初期确实要投入不少成本。需要采购工具、组建专门团队、优化流程。但从长远看,这是最划算的投入。因为一旦模型因为数据问题崩溃,损失的不仅是开发成本,还有用户信任 —— 而信任这东西,丢了可就很难找回来了。
行业里已经出现了专门的 AI 数据审核服务商,提供从源头检测到全流程监控的解决方案。这说明市场已经意识到这个问题的重要性。对于 AI 团队来说,现在不是考虑要不要做数据审核,而是怎么把这件事做好。
💡 最后想说的是,AI 发展到今天,已经过了 “有数据就先用起来” 的粗放阶段。想要做出真正可靠的 AI 产品,必须在数据质量上锱铢必较。过滤 AI 生成数据不是选择题,而是生存题。毕竟,再强大的模型,也经不起劣质数据的持续侵蚀。















