📊 别让 AI 喂饱 AI—— 当前训练数据的 “污染危机”
打开任何一个数据交易平台,你会发现标着 “高质量语料” 的数据包里,至少 30% 是 AI 批量生成的内容。这不是危言耸听,某头部大模型团队去年公开的报告显示,他们在清洗公开数据集时,发现 2023 年后新增的文本数据中,AI 生成内容占比已经达到 41.7%。
这些 AI 生成的文本看起来很 “规范”,语法正确、逻辑通顺,但用它们训练出来的模型会出现各种诡异问题。有团队做过实验,用含 30% AI 生成内容的数据集训练的模型,在事实性问答任务上准确率下降 28%,还会出现 “自我指涉” 的幻觉 —— 比如一本正经地引用不存在的论文,而那篇论文的标题其实是 AI 自己编的。
更麻烦的是,这种污染正在形成恶性循环。当你用被 AI 内容污染的模型生成新内容,再把这些内容加入训练集,就像给 AI 喂 “地沟油”,最后练出的模型连基本的事实判断力都会丢失。某垂直领域模型开发者吐槽,他们花三个月标注的行业数据,因为混入了一批 AI 生成的虚假案例,导致模型在实际应用中给出的解决方案全是错的。
🔍 智能筛选工具的三大 “火眼金睛” 能力
真正能解决问题的筛选工具,绝不是简单比对文本特征。现在市面上靠谱的系统,都具备这几个核心功能:
多模型交叉验证是基础操作。好的工具会同时调用 5 种以上不同架构的 AI 检测器,比如基于 Transformer 的分类模型、N-gram 概率分析模型,甚至还有专门检测 GAN 生成内容的对抗性识别算法。单一模型的误判率可能高达 15%,但交叉验证能把错误率压到 3% 以下。某工具商提供的测试数据显示,他们的系统在检测 GPT-4 生成的新闻稿时,准确率能稳定在 98.2%。
语义深度分析能看穿 “伪装者”。现在有些 AI 生成内容会故意加入错别字、口语化表达来模仿人类写作,但智能工具能通过分析语义连贯性识破这种把戏。它会追踪话题的演变路径,人类写作时话题转换往往有自然的跳跃,而 AI 生成的内容在逻辑链条上反而显得过于 “完美”,这种不自然的流畅度恰恰成了识别标志。
溯源追踪让数据可追溯。优质工具会建立数据指纹库,记录每段文本的首次出现时间、传播路径。如果一段文本在 2024 年突然出现在多个平台,却找不到任何更早的来源记录,系统就会标记它为高风险内容。某学术数据库使用这种方法,半年内清理了超过 10 万篇 AI 生成的虚假论文摘要。
🏭 三类场景最需要这样的 “数据净化器”
大语言模型训练团队是最大受益者。某千亿参数模型的研发负责人透露,他们引入智能筛选工具后,数据清洗成本降低了 62%。以前需要 50 人团队花两周时间筛选的 100 万条语料,现在系统 8 小时就能处理完,还能自动生成污染度报告,标出哪些段落是 AI 生成的,哪些是人类写作但质量低下的。
垂直行业数据集建设更离不开它。医疗、法律这些领域的数据敏感且专业,一旦混入 AI 生成的错误内容,后果不堪设想。某医疗 AI 公司用未筛选的数据训练诊断模型,系统竟然把 “急性阑尾炎” 误诊为 “胃溃疡”,原因是训练集中有篇 AI 生成的病例描述颠倒了症状顺序。引入筛选工具后,他们建立的专科语料库错误率从 11% 降到了 0.8%。
内容平台的 UGC 数据治理也很关键。论坛、问答社区每天产生海量用户内容,这些数据如果直接用来训练模型,等于把噪音当信号。某知识问答平台用智能工具处理了 500 万条历史回答,发现其中 17% 是 AI 生成的 “水帖”,这些内容看似回答了问题,实则没有任何实质信息。清理后,基于该平台数据训练的问答模型,用户满意度提升了 34%。
⚙️ 筛选工具背后的 “反制” 技术逻辑
想要理解这些工具为什么能识别 AI 内容,得先知道 AI 写作的 “破绽” 在哪里。人类写作时,大脑会同时处理语义、语法、情感等多个维度,而 AI 生成内容时,本质上是在预测下一个词的概率分布,这种机制会留下独特的 “指纹”。
词汇分布特征很明显。AI 生成的文本中,罕见词出现的概率往往低于人类写作,而且会高频使用某些 “安全词”。比如在英文写作中,GPT 系列模型特别喜欢用 “however”“therefore” 这些连接词,出现频率比人类高出 2.3 倍。中文 AI 生成内容则容易过度使用 “综上所述”“由此可见” 这类总结性短语,智能工具会统计这些特征词的出现频率,作为判断依据。
句子结构有规律可循。人类写长句时会自然出现结构松散甚至语法小错误,而 AI 生成的长句反而结构过于规整。智能筛选工具会分析句子的依存句法树,AI 生成的句子在主谓宾搭配上的熵值(混乱度)比人类写作低 30% 左右。这就像看书法,人类写的字总有细微的变化,而印刷体再精美也能看出机械感。
语义一致性检测更精准。高级筛选工具会用知识图谱做锚点验证,比如提到 “爱因斯坦” 时,人类可能会联想到 “相对论”“诺贝尔奖”,也可能突然跳到 “原子弹”,而 AI 生成内容更倾向于只围绕最相关的几个概念展开。系统会计算文本中概念跳转的 “合理距离”,超出正常范围就会被标记。某工具用这种方法,甚至能识别出经过人工修改的 AI 生成内容。
📌 选对工具的四个 “硬指标”
看准确率不能只听厂商宣传,得自己做测试。建议准备三类测试集:纯人类写作的文本(比如 2010 年前的新闻报道)、已知的 AI 生成内容、混合了两者的文本。好的工具在纯人类文本上的误判率要低于 5%,在纯 AI 文本上的识别率要高于 95%。某测评机构对 12 款工具的测试显示,表现最好的系统在混合测试集中的 F1 值能达到 0.97,而最差的只有 0.63。
处理速度决定能否落地。百万级别的语料库,优秀工具能在 24 小时内处理完毕,并且支持断点续传。某云计算厂商提供的 API 接口,单线程每秒能处理 3000 字文本,而有些开源工具处理同样规模的数据需要一周时间。如果是做实时数据筛选,响应延迟必须控制在 1 秒以内,否则会影响用户体验。
定制化能力很重要。不同领域的文本有独特特征,通用筛选模型在专业数据上表现会打折扣。好的工具应该支持上传领域语料进行微调,比如法律文本中 AI 生成的 “法条引用” 有特殊模式,经过微调后识别准确率能提升 15-20%。某律所使用定制化模型后,对 AI 生成的法律意见书识别率从 82% 提高到了 96%。
数据安全是底线。训练数据往往包含敏感信息,必须确保筛选过程中数据不会被泄露或滥用。选择工具时要看是否符合数据安全标准,比如是否支持本地部署,是否通过 ISO27001 认证,数据处理过程是否可审计。某金融机构就明确要求,所有数据筛选必须在私有云内完成,不允许任何数据流出防火墙。
🚀 未来一年,这些技术会改变筛选逻辑
实时筛选会成为标配能力。现在主流工具还是批量处理模式,未来会进化出实时拦截功能。想象一下,当你爬取网页数据时,系统能边下载边筛选,直接过滤掉 AI 生成的内容,效率会提升数倍。某浏览器插件已经实现了这个功能,用户在浏览网页时,能实时看到哪些段落被标记为 AI 生成,准确率达到 92%。
多模态筛选将解决图片、视频数据的问题。不只是文本,AI 生成的图片、音频、视频同样会污染训练数据。下一代工具会整合多模态识别技术,比如能同时检测视频中的 AI 生成人脸和字幕中的 AI 生成文本。某视频平台测试的系统,已经能识别出 90% 的 AI 生成虚拟主播视频。
对抗性训练让筛选更 “抗揍”。随着 AI 生成技术的进化,它们会刻意模仿人类写作的 “破绽” 来躲避检测。这会倒逼筛选工具采用对抗性训练方法,不断生成更难识别的 AI 内容来锻炼检测模型。就像杀毒软件和病毒的博弈,这种动态平衡会推动双方技术不断升级。
和区块链结合实现数据溯源。给每段人类创作的文本打上区块链时间戳,筛选工具通过验证时间戳就能确认内容的生成时间和创作者,从源头避免 AI 生成内容混入。某学术期刊已经开始试点这种方法,作者投稿时需要提供文本的区块链存证,编辑系统自动验证后才进入评审流程。
模型训练就像做饭,食材的新鲜度直接决定最终味道。智能筛选工具不是要阻止 AI 生成内容,而是要把它们放在合适的位置 ——AI 生成的内容可以用来做数据增强、场景模拟,但绝不能冒充人类原创内容混入训练库。
现在市面上已经有不少成熟的工具可供选择,从开源的 DetectGPT 到商业的 Originality.ai,从本地化部署的系统到 API 调用的云服务,总有一款能满足你的需求。关键是要认识到,数据质量比数量更重要,与其用百万条污染数据训练,不如用十万条干净数据深耕。
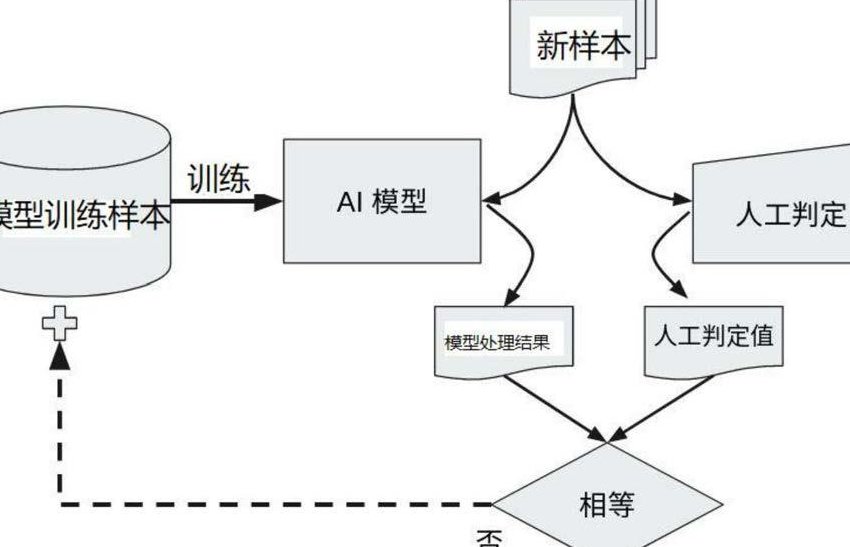
最后提醒一句,别迷信工具的 100% 准确率。再智能的系统也需要人工复核,特别是那些标记为 “低风险” 但实际是 AI 生成的内容,往往隐藏着最大的风险。人机协同,才是保证数据纯净的终极方案。
【该文章由diwuai.com
第五 ai 创作,第五 AI - 高质量公众号、头条号等自媒体文章创作平台 | 降 AI 味 + AI 检测 + 全网热搜爆文库🔗立即免费注册 开始体验工具箱 - 朱雀 AI 味降低到 0%- 降 AI 去 AI 味】















