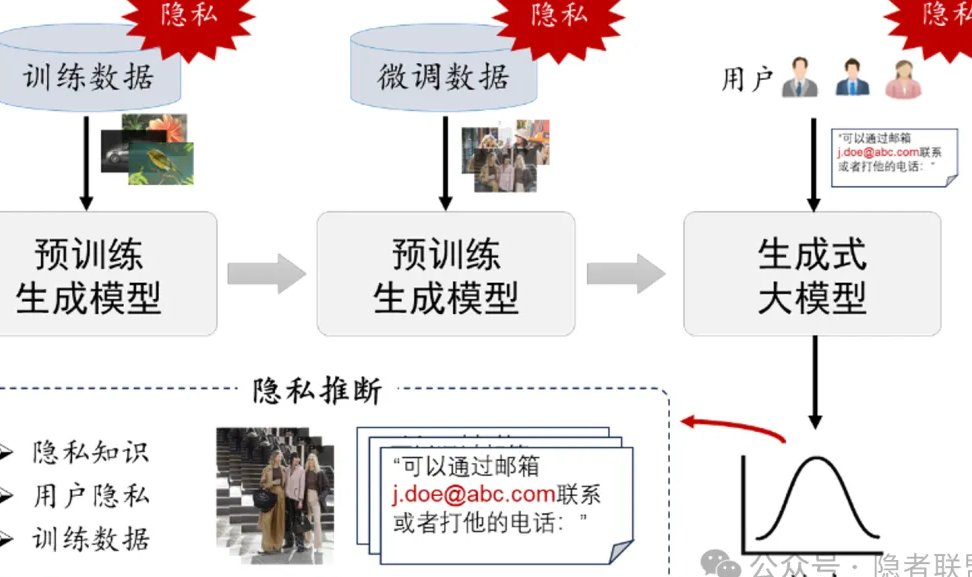
大模型文本检测技术火得一塌糊涂,现在不管是内容平台、教育机构还是企业,几乎都在想用它来解决问题。你看,学术领域用它查论文抄袭,社交媒体靠它过滤不良信息,企业内部拿它监控员工邮件。这技术确实厉害,能快速识别文本里的敏感内容、抄袭痕迹甚至情绪倾向。但用着用着,味道就有点变了。
🚨 技术滥用:从工具到 “枷锁” 的异化
无边界的内容审查正在侵蚀表达自由。有些平台为了所谓的 “安全”,把检测标准定得越来越严,甚至到了吹毛求疵的地步。用户发一条稍微带点批判性的评论,可能就被判定为 “敏感内容” 而限流;写篇随笔提到某个争议事件,直接就被系统删除。更夸张的是,有些教育机构用大模型检测学生的日记,美其名曰 “关注心理健康”,可这跟偷看别人的隐私有什么区别?表达自由是基本权利,过度检测只会让大家说话越来越谨慎,最后都变成 “沉默的大多数”。
商业领域的技术滥用更让人防不胜防。不少企业买了文本检测工具后,就开始对用户的所有数据 “一刀切” 检测。你在购物 APP 上跟客服的聊天记录,在理财平台留下的投资想法,甚至在医疗 APP 上咨询的病情描述,都可能被拿去训练模型或者卖给第三方。有用户反映,自己只是在某社交平台抱怨了一句产品质量,没过几天就收到了一堆推销竞品的广告,不用想也知道,是聊天内容被检测分析后泄露了。这种为了商业利益滥用技术的行为,正在透支用户的信任。
更可怕的是,技术滥用正在制造新的歧视和不公。大模型的检测逻辑是基于训练数据形成的,要是训练数据里藏着偏见,那检测结果自然也会带偏见。比如某些涉及少数群体的文本,明明没有问题,却因为模型对特定词汇的敏感而被误判。有个案例挺典型,某社区论坛上一位残障人士分享自己的生活经历,里面提到了一些描述身体状况的词汇,结果被系统判定为 “低俗内容” 下架了。这种带着偏见的检测,不仅伤害了当事人,更在无形中强化了社会对某些群体的刻板印象。
🔒 隐私保护:在技术扩张中节节败退
用户的文本数据正在变成 “透明人”。你可能觉得自己发的一条朋友圈、写的一封邮件只是个人行为,但在大模型文本检测面前,这些内容会被拆解成无数个数据点 —— 用词习惯、情感倾向、甚至隐藏的需求。更糟的是,很多平台在用户协议里藏着 “霸王条款”,一句 “使用本服务即同意我们对您的内容进行必要检测”,就把用户的知情权和选择权轻轻抹去。有调查显示,超过七成的用户根本没看过这些协议,等发现自己的隐私被泄露时,早就晚了。
数据滥用的链条比我们想象的更长。平台收集用户文本后,除了自己用,还会打包卖给数据公司。这些公司拿到数据后,又会二次加工,分析出用户的消费习惯、政治倾向甚至心理状态,再高价卖给广告商或者其他机构。前段时间曝光的某教育平台事件,就是把学生的作文检测数据卖给了培训机构,导致大量家长收到精准推销电话。这种 “检测 - 收集 - 售卖” 的产业链,让用户的隐私成了可以随意交易的商品。
现有法律对隐私保护的力度明显跟不上技术发展。虽然《个人信息保护法》里规定了处理个人信息要合法、正当、必要,但大模型文本检测的特殊性让这些条款很难落地。比如,怎么界定 “必要检测” 的范围?检测过程中产生的衍生数据算不算个人信息?这些模糊地带让很多企业钻了空子。监管部门往往是出了问题才去追责,可隐私一旦泄露,造成的伤害是很难挽回的。
⚖️ 平衡之路:在技术与伦理间找支点
明确技术应用的边界是第一步。不是所有场景都需要大模型文本检测,更不能搞 “一刀切”。比如,学术查重只需要检测论文是否抄袭,没必要分析作者的性格;企业监控邮件,只能针对工作相关内容,不能涉及员工的私人交流。平台应该公开检测的范围、标准和目的,让用户知道自己的哪些内容会被处理,处理后会用于什么用途。有个社交平台做得还不错,它会在用户发布内容前提示 “本条内容将进行敏感词检测,检测结果仅用于内容过滤”,虽然只是简单一句提示,却能让用户心里有数。
技术优化也能为隐私保护添砖加瓦。现在有些团队在研究 “联邦学习” 技术,简单说就是让模型在本地完成检测,不用把原始文本上传到云端,这样既能保证检测效果,又能减少数据泄露的风险。还有 “差分隐私” 技术,在检测时给数据加一些干扰信息,让别人无法还原出原始内容。这些技术如果能普及,就能在不牺牲检测效率的前提下,给用户隐私多一层保护。
用户的知情权和控制权必须得到强化。平台不能再用模糊的条款糊弄用户,应该用简单易懂的语言告诉用户:检测什么内容、为什么检测、数据会保存多久、能不能随时撤回同意。更重要的是,要给用户选择权 —— 可以选择哪些内容接受检测,哪些内容保密。就像有些 APP 的权限设置一样,用户可以随时打开或关闭文本检测功能。只有让用户真正掌握主动权,才能减少对技术的抵触。
🌐 未来展望:伦理建设要跑赢技术迭代
行业自律比监管更及时有效。与其等政府出台细则,不如企业先行动起来。可以成立行业协会,制定大模型文本检测的伦理准则,比如 “最小必要原则”—— 只用最少的数据、在最短的时间内完成检测;“透明原则”—— 公开检测逻辑和数据用途;“纠错原则”—— 建立误判申诉通道。现在已经有几家头部企业在做这件事了,要是能形成行业共识,就能避免恶性竞争和技术滥用。
法律法规得跟上技术的脚步。现有法律对大模型的约束太笼统,需要针对性地细化。比如,明确禁止将文本检测用于监控个人隐私、禁止未经同意的数据分析、规定数据保存的最长时限。同时,要加大对违法企业的处罚力度,让它们不敢轻易越界。国外有些地方已经开始试点 “数据保护影响评估” 制度,企业用大模型检测文本前,必须先评估对用户隐私的影响,通过审核才能使用,这种做法值得借鉴。
公众的数字素养也得同步提升。很多人对大模型文本检测一无所知,更不知道自己的隐私可能正在被侵犯。学校、社区可以多开展科普活动,告诉大家技术的原理、风险和防范方法。比如,教大家怎么看懂用户协议,怎么关闭不必要的检测权限,遇到隐私泄露该怎么维权。只有公众意识提高了,才能形成倒逼企业规范行为的力量。
大模型文本检测本身是个好技术,能帮我们解决很多以前解决不了的问题。但技术就像一把刀,用得好能切菜,用不好就会伤人。现在的问题是,这把刀的使用边界太模糊,很容易伤到用户的隐私和权利。想要平衡技术滥用和隐私保护,不能只靠某一方努力 —— 企业要守住伦理底线,法律要划清红线,用户要提高警惕。只有三方合力,才能让技术真正服务于人,而不是变成伤害人的工具。毕竟,技术的进步应该让人更自由,而不是更压抑。
【该文章由diwuai.com
第五 ai 创作,第五 AI - 高质量公众号、头条号等自媒体文章创作平台 | 降 AI 味 + AI 检测 + 全网热搜爆文库🔗立即免费注册 开始体验工具箱 - 朱雀 AI 味降低到 0%- 降 AI 去 AI 味】















