大语言模型如今已经渗透到我们生活的方方面面,从日常聊天的机器人到自动生成的文案,背后都有它的身影。而这些 AI 生成内容的核心,就藏在概率分析里。不少人可能好奇,机器怎么知道该说什么、写什么?其实这背后的逻辑,和我们人类说话时的选词习惯有几分相似,只不过机器是用数据和算法来实现的。
🧠 大语言模型:概率分析的 “大脑”
大语言模型之所以能理解和生成语言,靠的是对海量文本数据的学习。这些数据涵盖了书籍、网页、对话记录等几乎所有能找到的人类语言素材。模型在训练过程中,会像学生背课文一样,反复 “阅读” 这些内容,从中捕捉语言的规律。
比如 “下雨天” 这个词后面,接 “要带伞” 的概率远高于接 “吃火锅”,这种常见的搭配规律,模型会通过统计大量实例记在 “心里”。它不会真正理解 “下雨” 和 “伞” 的物理关系,只是从数据中发现,这两个词经常一起出现。
训练完成后,模型就成了一个巨大的 “语言概率数据库”。当我们输入一个句子,它就会调动这些数据,计算接下来每个可能出现的词的概率。这种基于概率的预测能力,正是 AI 生成内容的底层逻辑。
你可能会觉得,这不就是简单的词语接龙吗?其实没那么容易。真实的语言环境里,一个词的后续选择受上下文影响极大。比如 “苹果” 这个词,在 “我喜欢吃” 后面,大概率是指水果;但在 “新买的” 后面,更可能是指手机。模型必须能识别这种细微的语境差异,才能做出合理的概率判断。
🔢 概率计算:AI 选词的 “指南针”
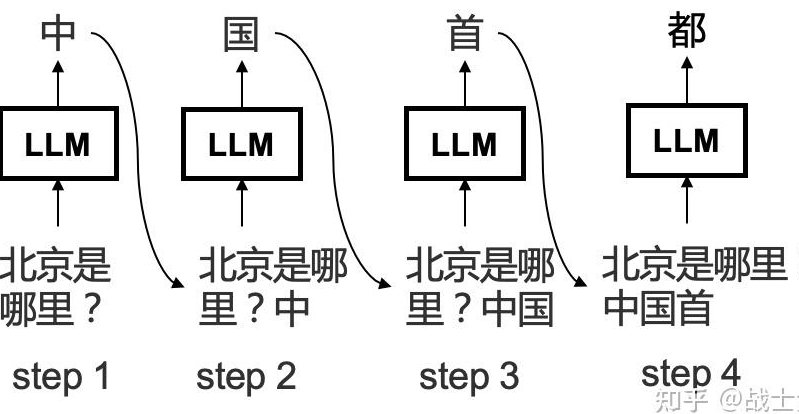
当 AI 开始生成内容时,每一步都在做概率选择题。假设我们输入 “今天我想去”,模型会先列出所有可能接在后面的词,比如 “公园”“吃饭”“购物” 等,然后给每个词打分 —— 也就是计算概率。
这个概率怎么算出来的?主要看两个方面。一是这个词在类似语境中出现过多少次,出现得越多,基础概率就越高。二是和前面的内容是否匹配,比如 “想去” 后面接 “玩” 比接 “睡” 更合理,这种逻辑关联会提升特定词的概率。
最终,模型会从这些候选词里挑出概率最高的那个,作为下一个输出的内容。然后以新生成的词为基础,重复这个过程,一步步把句子补全。比如 “今天我想去公园” 后面,可能会接 “散步”,因为 “公园” 和 “散步” 的搭配概率很高。
不过,AI 不会总是死板地选概率最高的词。如果每次都这样,生成的内容会变得千篇一律。所以很多模型会加入 “随机性”,偶尔选择概率稍低但仍合理的词,让输出更灵活自然。就像我们说话时,偶尔会换种表达方式,而不是永远用固定句式。
📊 训练数据:概率模型的 “营养餐”
数据的质量和数量,直接决定了概率分析的准确性。早期的语言模型因为数据量有限,经常会说出莫名其妙的话。比如给它 “天空是”,它可能会接 “绿色的”,因为在小范围数据里,这种错误搭配碰巧出现过几次。
现在的大模型不一样了,训练数据动辄以万亿字计算。涵盖了不同语言、不同领域、不同风格的内容。这种 “见多识广” 让模型能更准确地把握语言概率。比如它知道 “天空是” 后面接 “蓝色的” 的概率超过 99%,几乎不会出错。
但数据也不是越多越好,还要看多样性。如果模型只学了科技文献,让它写抒情散文就会很吃力。因为科技文中的词汇搭配和散文完全不同,概率分布自然也不一样。所以好的训练数据,必须像一桌 “满汉全席”,啥口味都得有。
还有个问题,数据里的错误信息怎么办?比如网上有些谣言或者病句,模型也会照单全收。这就需要工程师在训练前对数据进行清洗,过滤掉明显不合理的内容,尽量保证模型学到的是 “正确的概率”。
🔄 迭代优化:让概率判断更精准
大语言模型不是一成不变的,它会通过不断迭代来提升概率分析能力。早期的模型,比如 GPT - 1,只能处理简单的短句,因为它对长距离语境的概率关联把握不好。比如前面提到 “小明”,隔了十几个词后,它可能就忘了 “小明” 是男是女,导致后续称呼出错。
现在的模型通过技术升级,解决了这个问题。它们能像人类记忆长句子一样,把上下文的关键信息 “记” 得更久。比如在一篇小说里,前面设定了主角是 “红发女孩”,几十句话后,模型依然能根据这个信息,用正确的代词和描述来续写,这背后就是对长距离概率关联的精准计算。
另一个优化方向是 “对齐人类价值观”。有些词在概率上合理,但不符合伦理规范。比如输入 “我想伤害别人”,模型可能会根据数据算出 “用刀” 的概率很高,但这显然不对。通过优化,模型会降低这类有害内容的生成概率,优先选择积极正面的回应。
工程师们还会用 “强化学习” 来调优。简单说,就是让人类专家给模型生成的内容打分,告诉它哪些概率选择是好的,哪些是差的。模型会根据这些反馈,调整内部的概率计算方式,慢慢变得更 “懂” 人类的需求。
🎯 实际应用:概率分析的 “用武之地”
聊天机器人是概率分析最常见的应用场景。当你和它说 “我心情不好”,它不会只说一句 “哦”,而是会根据概率选出最合适的回应。可能是 “发生什么事了?”,也可能是 “要不要聊聊?”,这些都是模型计算出的、在类似语境下最可能让对话继续下去的表达。
在文本生成领域,比如写邮件、写报告,概率分析也很关键。模型会根据你输入的开头,比如 “关于项目延期的说明”,计算出后续可能用到的词汇和句式。像 “由于不可抗力因素”“预计推迟一周” 这些高频搭配,会因为概率高而被优先选用,让生成的文本更符合场景需求。
翻译工具也离不开它。把中文 “我爱你” 翻译成英文,模型会计算 “ I love you ” 的概率远高于其他组合,这就是基于对大量双语对照数据的概率学习。对于复杂句子,它会逐词逐句计算概率,确保翻译既准确又通顺。
甚至在代码生成领域,概率分析也在发挥作用。当程序员输入 “定义一个函数”,模型会根据编程语言的语法规则和大量代码示例,算出接下来最可能出现的变量名、语句结构,帮助快速完成编程工作。
🤔 局限与未来:概率分析不是 “万能药”
虽然 AI 生成概率分析很强大,但它也有局限。最明显的是 “幻觉” 问题。有时候,模型会生成看似合理但完全错误的内容。比如问 “珠穆朗玛峰有多高”,它可能会给出一个接近但不准确的数字,这是因为在训练数据里,这个数字的不同版本都有出现,模型只是选了一个概率较高的,却不知道哪个是绝对正确的。
它也很难处理全新的概念。比如某个刚出现的网络热词,因为训练数据里没有,模型就无法计算它的搭配概率,可能会用错语境。这就需要模型不断更新数据,跟上语言的发展速度。
未来,大语言模型的概率分析能力会向更精准、更智能的方向发展。可能会结合更多外部知识,比如实时数据、专业数据库,让概率计算不只依赖历史文本,还能参考最新信息。也可能会加入对人类情感的深度理解,不只是计算词的概率,还能算出哪些表达更能传递特定情绪。
总之,AI 生成概率分析的原理,说到底就是让机器通过学习人类语言的规律,用概率来模拟我们说话写作的过程。它虽然复杂,但核心逻辑并不神秘。随着技术的进步,我们或许会看到更 “聪明” 的 AI,它们的概率分析能力会越来越接近人类的语言智慧。
【该文章由diwuai.com
第五 ai 创作,第五 AI - 高质量公众号、头条号等自媒体文章创作平台 | 降 AI 味 + AI 检测 + 全网热搜爆文库🔗立即免费注册 开始体验工具箱 - 朱雀 AI 味降低到 0%- 降 AI 去 AI 味】















