🤖 先搞懂:AI 代码为啥总撞衫?
AI 写代码的逻辑,说白了就是 “抄作业” 的高级版。它靠着啃下海量开源仓库、技术论坛里的代码片段,把这些东西拆解成无数个小模块,等到用户提问时,就从自己的 “素材库” 里挑出合适的模块拼起来。
这就有个大问题 —— 大家问的问题往往差不多。比如 “怎么写个登录功能”“如何实现数组去重”,AI 接收到的需求高度重合,它从素材库里挑的模块自然也大同小异。你用 ChatGPT 写,我用 Claude 生成,出来的代码能不一样吗?
更麻烦的是,AI 特别 “念旧”。那些被反复收录的经典实现方式,比如冒泡排序的标准写法、单例模式的常规套路,AI 生成时会优先选用。这就导致哪怕是不同场景,只要涉及类似功能,代码结构就容易撞车。
还有个容易被忽略的点,很多人用 AI 生成代码时,给的提示词太笼统。就说 “写个文件上传功能”,没说清楚用什么框架、有没有特殊需求,AI 只能按最通用的模板来生成,结果自然千篇一律。
🔍 相似度高的坑:不止是 “抄作业” 那么简单
最直接的麻烦是学术不端。学生党用 AI 写课程作业、毕设代码,一旦被查重系统揪出相似度超标,轻则返工重写,重则影响成绩甚至毕不了业。现在高校的代码查重系统越来越严,像 Turnitin、知网都能精准识别 AI 生成的套路化代码。
职场人也躲不过。公司项目里用了高相似度的 AI 代码,万一这些代码来自有版权的开源项目,很可能触发法律风险。去年就有企业因为用了 AI 生成的疑似侵权代码,被开源社区起诉,最后赔了不少钱。
从技术角度说,相似度高的代码往往带着 “通病”。比如冗余的循环结构、低效的内存处理,这些都是 AI 从旧代码里学来的坏习惯。直接用的话,后期维护时会发现到处是坑,改一处牵一发而动全身。
团队协作时更尴尬。好几个人都用 AI 生成代码,提交到仓库后发现大家写的模块高度相似,合并代码时冲突不断。更糟的是,出了 bug 都不知道该找谁修,因为代码长得太像,分不清是谁的 “手笔”。
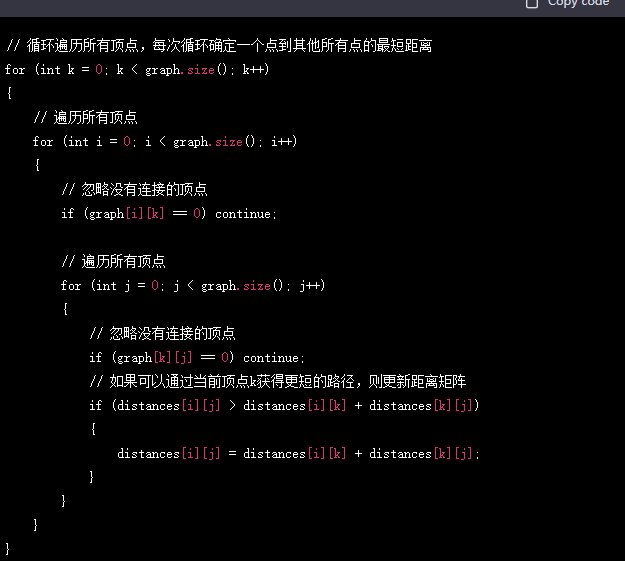
🛠️ 降重原则一:拆解功能,打乱 “积木顺序”
AI 生成的代码就像搭好的积木,每个功能模块都是固定的组合方式。要降重,第一步就是把这些积木拆开,重新排列。
比如一个用户注册功能,AI 通常会按 “接收参数→验证格式→连接数据库→保存数据→返回结果” 的顺序写。你可以把验证格式的步骤拆成独立函数,放到工具类里;把数据库操作做成一个服务层,调用的时候再引入。顺序一变,代码结构立刻就不一样了。
变量名和函数名是重灾区。AI 爱用 “userName”“getData” 这类通用名称,你得换成更具体的。比如处理用户手机号的变量,别叫 “phone”,改成 “userRegisterPhoneNum”;查询订单的函数,别叫 “queryOrder”,改成 “fetchUserRecentThreeMonthOrder”。名称一具体,相似度马上降下来。
还有注释,AI 写的注释要么太简单,要么和代码重复。你可以换成自己的理解来写,比如 AI 注释 “// 循环添加元素”,你可以写成 “// 遍历用户列表,将符合条件的 id 存入数组,用于后续权限校验”。注释风格变了,整体感觉也会不同。
试试这个小技巧:把长函数拆成多个短函数。AI 总喜欢写几百行的大函数,你按功能拆成 5 - 10 行的小函数,再用一个主函数来调用。代码结构会更清晰,而且和原来的版本差异很大。
🛠️ 降重原则二:换种思路实现,避开 “标准答案”
同一件事,实现方法不止一种。AI 总爱用 “标准答案”,你换个思路就行。
比如判断字符串是否为空,AI 大概率会写 “if (str == null || str.length () == 0)”。你可以换成 “if (str == null || str.isEmpty ())”,或者用工具类 “StringUtils.isEmpty (str)”。效果一样,代码却不一样。
处理集合的时候更明显。AI 用 for 循环遍历,你可以换成增强 for 循环、迭代器,或者 Java 8 以后的 stream 流。比如 “for (int i = 0; i < list.size (); i++)”,换成 “list.forEach (item -> { ... })”,一下子就有了区分度。
算法层面也能动手脚。比如排序,AI 默认用冒泡排序,你可以换成选择排序;处理日期,AI 用 SimpleDateFormat,你可以换成 LocalDateTime;就连异常处理,AI 用 try-catch,你可以改成在方法上 throws,让上层来处理。
数据库操作也有文章可做。AI 写查询语句喜欢用 “*” 来获取所有字段,你改成具体的字段名;分页查询用 limit,你可以换成 row_number () 函数;插入数据用 insert into,你可以试试批量插入 “insert into ... values (...), (...), (...)”。
别小看这些小改动,积累起来差异就很大了。关键是要记住:实现功能的路径有很多,别被 AI 的 “标准答案” 框住。
再举个例子,AI 生成单例模式时,总爱用饿汉式或者懒汉式。你可以换成静态内部类实现,或者枚举方式,甚至用 Spring 的依赖注入来保证单例。原理不变,代码却完全不同。
🛠️ 降重原则三:引入个性化 “标记”,增加 “专属特征”
加入一些只有你会用的 “个性化代码”,能让相似度断崖式下降。
比如在工具类里加一个自己定义的常量,像 “private static final String PROJECT_PREFIX = "user_center_v2_";”,然后在生成 ID、拼接字符串的时候用上。AI 的代码里没有这个常量,自然就不一样了。
调用一些冷门的 API 或者工具类。比如处理 JSON,AI 常用 Jackson,你可以换成 Gson;处理日期,不用 Date,用 Joda-Time。这些库功能类似,但方法名和使用方式不同,能有效降低相似度。
还有项目里的自定义规范,比如公司要求的日志格式、异常处理方式。AI 不知道这些,你按自己的规范来写,比如统一用 “LogUtils.error ("用户注册失败", e)” 记录错误,而不是 AI 默认的 “e.printStackTrace ()”。
可以加一点 “无用但无害” 的代码。比如在循环里加一句调试用的日志(上线前删掉),或者定义一个暂时用不上的变量。这些小细节不会影响功能,却能让你的代码和 AI 生成的版本区别开。
📝 实战技巧:降重后的 “双检” 很重要
降重完了别直接用,先自己检查一遍。
第一步,跑一遍代码,确保功能没问题。拆改的时候很容易不小心改坏逻辑,比如把判断条件的 “&&” 改成 “||”,结果就完全错了。
第二步,用查重工具测一下。推荐几个常用的:代码查重可以用 Checkstyle、PMD,学术场景可以用 Turnitin 的代码检测功能,企业团队可以用 SonarQube。测的时候注意对比原始的 AI 代码,确保重复率降到可接受范围(一般低于 15%)。
还有个小窍门:找同事看看你的代码。如果他能一眼看出 “这像是 AI 写的”,说明降重还不到位。要是他觉得 “这风格挺像你写的”,那就差不多了。
别忽略版本控制记录。提交代码时,commit 信息写详细点,比如 “重构用户注册模块,拆分验证逻辑,替换变量名”。万一后期被质疑,这些记录能证明代码是你改过的。
⚠️ 避坑提醒:降重不是 “瞎改”,这些底线不能碰
降重的前提是保证代码能跑。别为了降重乱改逻辑,比如把 “i++” 改成 “i = i + 1” 没问题,但把循环条件 “i < 10” 改成 “i <= 9” 虽然效果一样,可要改复杂逻辑就容易出问题。
别破坏代码规范。公司有编码规范的话,按规范来改。比如命名规则、缩进格式、括号位置,乱改只会让代码更难维护,还可能引入新的问题。
开源代码要注意版权。别为了降重,直接复制其他开源项目的代码过来改。哪怕改了变量名,核心逻辑一样的话,还是可能侵权。最好是理解原理后,用自己的方式重写。
别过度降重。有些人为了降到 0 相似度,把简单的代码改得特别复杂,比如用三目运算符嵌套代替 if-else,结果后期自己都看不懂。降重是为了避开重复,不是为了制造麻烦。
🎯 最后说句大实话
AI 生成的代码就像半成品,拿来直接用肯定不行。降重不是 “做手脚”,而是把它变成 “自己的东西” 的过程。
真正的程序员,看的不是代码长得怎么样,而是逻辑清不清晰、能不能解决问题。把 AI 代码当成参考,再用自己的经验和思路去改造,既能提高效率,又能避免相似度问题。
记住,降重的核心不是 “和 AI 不一样”,而是 “让代码真正属于你”。做到这一点,相似度什么的,根本不是问题。
【该文章由diwuai.com
第五 ai 创作,第五 AI - 高质量公众号、头条号等自媒体文章创作平台 | 降 AI 味 + AI 检测 + 全网热搜爆文库🔗立即免费注册 开始体验工具箱 - 朱雀 AI 味降低到 0%- 降 AI 去 AI 味】















