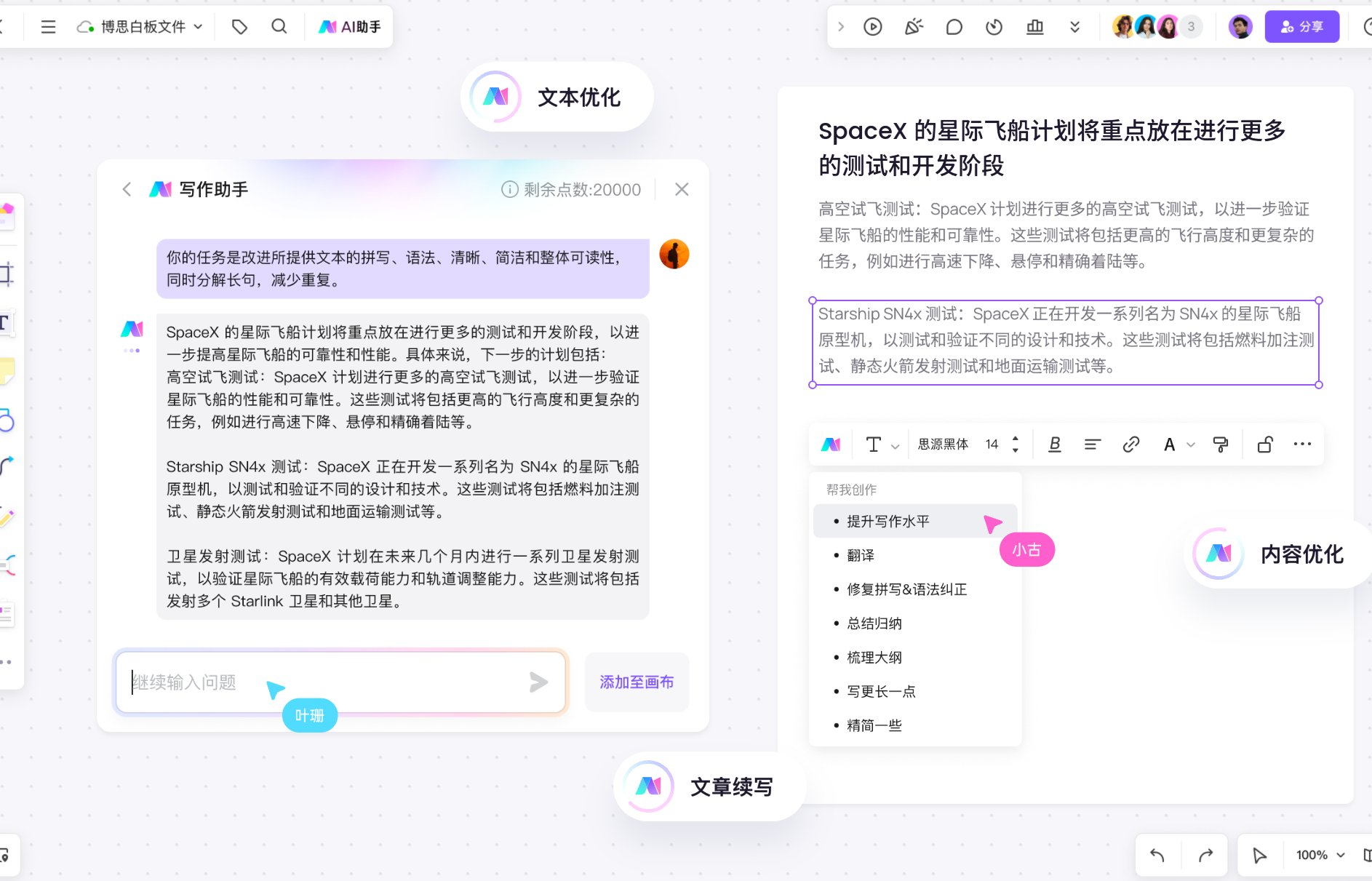
现在市面上免费 AI 写作软件越来越多,大家在享受便利的同时,也开始关心这些软件的数据来源和版权问题。今天咱们就好好聊聊这两个关键点。
📡 免费 AI 写作软件的数据从哪儿来?
免费 AI 写作软件的数据来源其实挺多样的。像公开的网络文本就是很常见的一种,比如网上的文章、博客、书籍等,这些公开信息能让 AI 学习到各种语言表达和知识。有些软件还会用学术论文作为数据源,比如Ahelp.com的 AI 写作工具,就参考了 200 多万篇学术论文,这样能让生成的内容更有专业性。
用户输入的数据也很重要。当你使用这些软件时,输入的文字、指令等都会成为 AI 学习的一部分,帮助它更好地理解你的需求,生成更符合你要求的内容。还有一些软件会和其他平台合作,获取授权内容,比如和新闻网站、文学平台合作,这样能保证数据的合法性和多样性。
不过,也有一些软件可能会从一些未经授权的渠道获取数据。比如抓取某些网站的内容,却没有得到网站的许可,这种情况下就可能存在版权风险。所以大家在选择软件的时候,最好了解一下它的数据来源是否合法。
⚠️ 免费 AI 写作软件有版权风险吗?
说到版权风险,还真不能掉以轻心。从法律层面来看,AI 生成的内容是否受版权保护,主要取决于用户的独创性投入。如果只是输入简单的提示词,让 AI 生成内容,这种情况下生成的内容可能不构成作品,因为缺乏用户的独创性表达。比如你输入 “写一篇关于猫的文章”,AI 生成的内容可能就只是一些常见的描述,很难体现出你的独特创意。
但如果你在使用过程中,对提示词进行了详细的设计,或者对生成的内容进行了大量的修改和调整,融入了自己的独创性智力投入,那么这样的内容就可能受版权保护。比如你详细描述了猫的性格、生活场景等,AI 根据你的描述生成了一篇生动的文章,你又对文章进行了润色和修改,这样的文章就可能属于你的作品。
实际案例也能说明问题。之前有一个 “奥特曼案”,AI 平台生成的绘画形象和享有版权的奥特曼形象很相似,而且平台还通过销售会员等方式获利,结果就被法院认定构成著作权侵权,需要赔偿权利人的损失。这就提醒我们,AI 生成的内容如果和现有的版权作品实质性相似,就可能引发侵权问题。
另外,软件本身的数据来源如果不合法,也会带来风险。如果软件使用了未经授权的版权内容进行训练,那么生成的内容也可能存在侵权隐患。就像法国出版行业起诉 Meta,指控其未经授权使用受版权保护的作品训练 AI 模型,这就是因为数据来源不合法导致的版权纠纷。
🛡️ 怎么降低使用免费 AI 写作软件的版权风险?
虽然存在版权风险,但我们可以通过一些方法来降低风险。首先,在使用软件时,要尽量确保数据来源合法。选择那些明确说明数据来源、有正规授权的软件,避免使用来源不明的软件。比如 Rytr.me 就明确声明用户拥有生成内容的版权,但用户需要自行确保内容的合法性,这样的软件相对来说更可靠一些。
在生成内容后,仔细检查内容是否与现有版权作品相似也很重要。可以使用一些版权检测工具,如千笔 AI 论文、Copyleaks 等,这些工具能帮助你检测内容是否存在侵权问题。如果发现有相似度过高的部分,及时进行修改。
保存创作过程的证据也必不可少。比如保存提示词内容、参数设置、修改记录等,这些证据能在必要时证明你对生成内容的独创性贡献。像北京互联网法院在审理 AI 生成内容著作权案件时,就很重视用户提供的创作过程记录。
📜 不同地区的版权规定有啥不一样?
不同地区对于 AI 生成内容的版权规定存在差异。在美国,版权局的裁决倾向于用户需证明独创性,简单提示词生成的内容可能无法获得保护。而欧盟则更加严格,根据《人工智能法案》,基础模型的供应商需要声明是否使用受版权保护的材料来训练 AI,如果违规,可能会面临高达 3000 万欧元或公司全球年收入 6% 的罚款。
法国的案例也显示出欧盟在版权保护上的严格态度。法国出版行业起诉 Meta,就是因为 Meta 未经授权使用版权作品训练 AI 模型,这在欧盟是不被允许的。所以如果你在欧盟地区使用免费 AI 写作软件,一定要更加注意数据来源和版权问题。
总的来说,免费 AI 写作软件的数据来源多样,版权风险确实存在,但我们可以通过选择合法软件、确保独创性投入、检查内容相似性、保存证据等方法来降低风险。同时,了解不同地区的版权规定,也能帮助我们更好地使用这些软件,避免侵权问题。大家在使用过程中一定要谨慎,保护好自己的权益,也要尊重他人的版权。
该文章由diwuai.com第五 ai 创作,第五 AI - 高质量公众号、头条号等自媒体文章创作平台 | 降 AI 味 + AI 检测 + 全网热搜爆文库
🔗立即免费注册 开始体验工具箱 - 朱雀 AI 味降低到 0%- 降 AI 去 AI 味
🔗立即免费注册 开始体验工具箱 - 朱雀 AI 味降低到 0%- 降 AI 去 AI 味






AIGC引擎如何生成病毒式标题")








