📌 根本原因一:训练数据的 “先天性局限”
AI 生成内容的查重率问题,根源往往藏在它的 “学习材料” 里。目前主流的大语言模型,训练数据大多来自公开互联网资源,像常见的新闻网站、学术论文库、社交媒体内容等。这些数据看似庞大,实则存在严重的重叠性。
举个例子,当多个模型都用维基百科的同一批词条、同一批经典文学作品做训练时,它们对相似主题的表述会不自觉地趋同。你让不同 AI 写 “李白的诗歌成就”,大概率都会提到 “盛唐气象”“浪漫主义风格”“《将进酒》代表作” 这些高频表述。这些内容本身是公开知识,但当 AI 反复生成时,就成了查重系统眼里的 “可疑目标”。
更麻烦的是,训练数据的时效性也会拖后腿。很多模型的训练数据截止到某一时间点,比如 2023 年或 2024 年初。这意味着对于新出现的事件、概念,AI 缺乏独特的训练素材,只能基于旧有数据进行推演。生成内容时,自然容易和已存在的旧内容 “撞车”。
还有个容易被忽视的点:训练数据的 “质量筛选” 不足。不少模型为了追求数据量,会纳入大量低质重复内容。比如某些营销软文、拼凑的博客文章,本身就存在抄袭问题。AI 学了这些内容,生成的文字能不带上 “查重基因” 吗?
📌 根本原因二:生成机制的 “同质化倾向”
AI 的写作逻辑和人类有本质区别。人类写作是基于个人经验、思考和独特表达习惯,AI 则是通过算法预测 “下一个词该是什么”。这种预测模式依赖于训练数据中的 “概率分布”—— 也就是某个词在特定语境下出现的频率。
这就导致一个结果:AI 更倾向于使用训练数据中出现频率高的词汇、句式和段落结构。比如写 “环境保护” 主题,它大概率会选择 “绿水青山”“可持续发展”“低碳生活” 这些高频搭配,而不是更具个性的表达。
而且,大多数 AI 生成内容时会默认 “安全模式”。为了避免错误,它会优先选择经过验证的、被广泛接受的表述,而不是冒险尝试新颖的表达方式。这种 “求稳” 的特性,进一步加剧了内容的同质化。
你可能遇到过这种情况:用不同 AI 工具生成同一主题的内容,结果发现它们的核心观点、甚至某些句子都惊人地相似。这不是巧合,而是它们共享了相似的训练数据和生成逻辑。
📌 技术局限:AI 难以突破的 “特征印记”
查重系统之所以能识别 AI 内容,是因为 AI 生成的文字会留下独特的 “数字指纹”。这些特征包括特定的标点使用习惯(比如逗号和句号的比例)、句子长度的分布规律、甚至是某些高频出现的连接词。
举个具体的例子,有研究发现某知名 AI 模型生成的英文内容中,“however” 和 “nevertheless” 的使用比例明显高于人类写作。中文 AI 也有类似问题,比如过度依赖 “首先”“其次”“综上所述” 这类逻辑连接词。
这些特征不是 AI 故意留下的,而是算法运行的必然结果。查重系统通过机器学习这些特征,就能快速识别出哪些内容可能来自 AI。更麻烦的是,即使你对 AI 生成的内容做了简单修改,这些深层特征也很难完全消除。
另外,AI 在处理特定领域内容时,更容易暴露痕迹。比如写学术论文时,AI 对参考文献的引用格式往往有固定模式;写产品评测时,它对优缺点的描述顺序也相对固定。这些模式化的表达,都成了查重系统的 “靶子”。
📌 应用场景:哪些情况下查重率问题最突出?
学生群体可能最深有体会。用 AI 写作业、论文时,查重率经常爆表。这是因为教育领域的查重系统(比如知网、Turnitin)数据库和 AI 训练数据有大量重叠。你用 AI 生成的内容,很可能和数据库中已有的论文、期刊文章高度相似。
营销文案领域也常遇麻烦。很多公司用 AI 批量生成产品描述、短视频脚本,结果发现不同平台的内容重复率过高,不仅影响搜索引擎排名,还可能被判定为 “垃圾内容”。
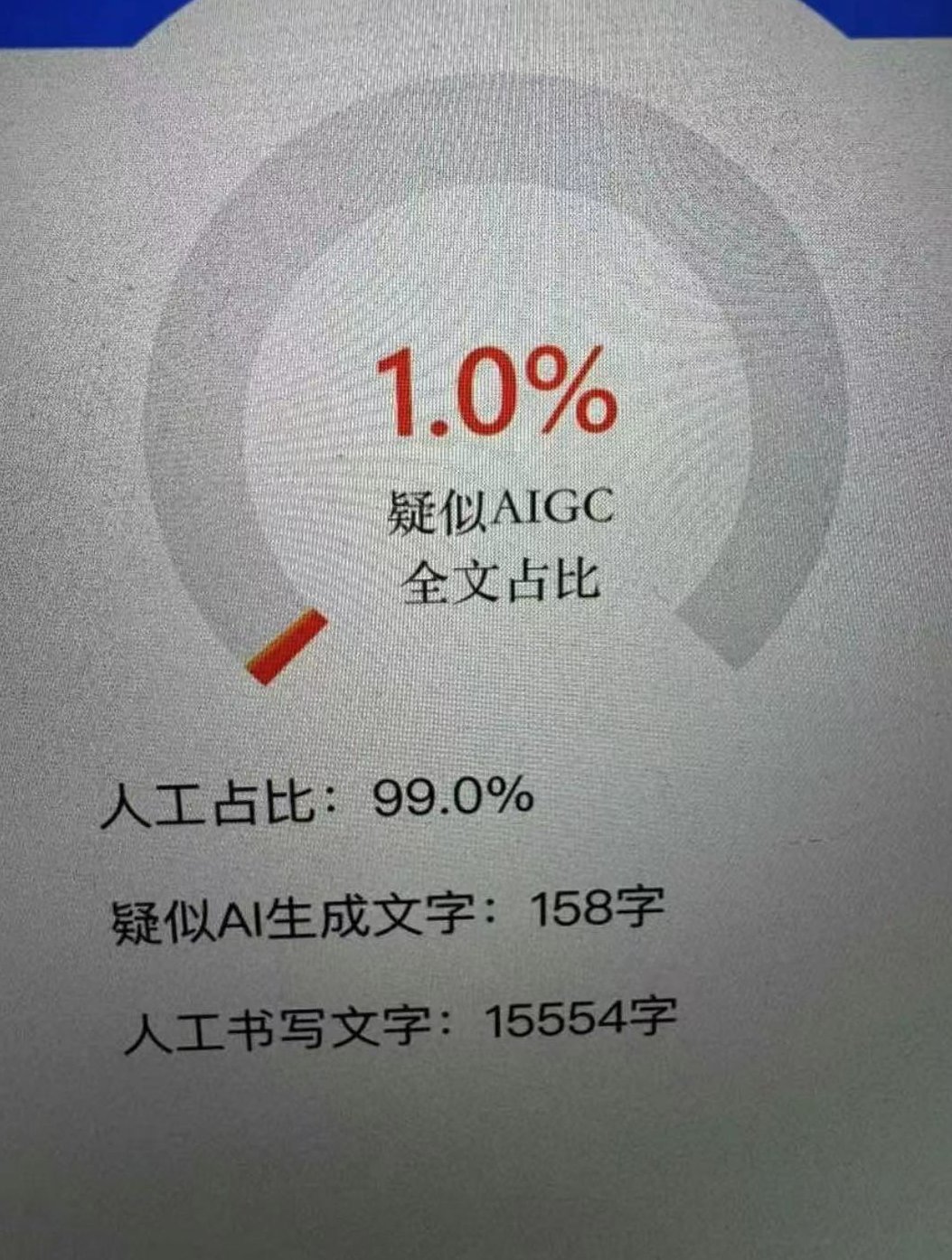
自媒体创作者更是深受其害。用 AI 写的文章,即使主题新颖,也可能因为表述方式和已有内容相似,被平台判定为 “低质重复”,影响推荐量。有博主测试过,同一篇 AI 生成的文章,在多个平台发布后,原创标识通过率不到 30%。
法律文书、学术论文等对原创性要求极高的领域,AI 内容的查重问题更致命。这些领域的查重系统灵敏度更高,哪怕是局部表述相似,都可能被认定为 “抄袭”,造成严重后果。
📌 解决方案一:从生成源头降低重复率
调整 AI 生成参数是最直接的方法。大多数 AI 工具都提供 “创造性”“随机性” 相关的设置。比如在 ChatGPT 中,提高 “temperature” 参数(建议设为 0.8-1.2),能让生成内容更具随机性,减少和已有内容的重合。
选择更专业的垂直领域模型也有帮助。通用大模型因为训练数据太杂,更容易生成重复内容。而专注于某一领域的模型(比如法律、医学专用 AI),训练数据更精准,生成的内容独特性也更高。
还有个小技巧:给 AI 更具体的提示词。不要只说 “写一篇关于气候变化的文章”,而是明确要求 “用渔民的视角写气候变化的影响,包含 3 个具体生活案例”。提示词越具体,AI 生成的内容就越难和已有内容重复。
多模型交叉生成也是个好办法。先用模型 A 生成初稿,再用模型 B 基于初稿进行改写,最后用模型 C 润色。不同模型的生成逻辑有差异,交叉使用能有效打破单一模式,降低重复率。
📌 解决方案二:人工优化的关键技巧
拿到 AI 生成的内容后,不要直接使用。先通读一遍,找出那些 “一看就像 AI 写的句子”—— 通常是那些过于工整、缺乏个性的表达。比如 “随着社会的不断发展,人们的生活水平日益提高” 这类套话,一定要彻底改写。
替换同义词是基础操作,但要注意语境。不要简单把 “重要” 换成 “关键”,可以根据上下文调整为 “不可或缺”“影响深远” 等更精准的表达。对于专业术语,要确保替换后的词语符合行业规范。
改变句式结构更重要。AI 偏爱中等长度的句子,你可以刻意增加短句和长句的比例。比如把 “人工智能技术发展迅速,它在医疗领域的应用越来越广泛” 拆成 “人工智能技术正以前所未有的速度发展。医疗领域,它的应用场景每天都在拓展。”
加入个人经验和案例是提升原创性的杀手锏。AI 生成的内容往往缺乏具体细节,你可以补充自己的观察、经历或独特案例。比如写旅游攻略时,在 AI 初稿基础上,加入你去过的某个小众景点的具体感受。
📌 解决方案三:借助工具提升原创度
现在有不少专门针对 AI 内容去重的工具,比如 QuillBot、Paraphraser 等。这些工具能在保持原意的前提下,大幅改写句子结构和用词,比人工修改效率高得多。但要注意,这类工具也有局限性,过度使用可能导致语句不通顺。
查重工具本身也能帮你优化内容。用知网、万方等权威查重系统检测后,重点修改标红部分。很多人不知道,查重报告中的 “相似来源” 其实是很好的参考 —— 你可以看看 AI 生成的内容和哪些已有文章重复,然后针对性地避开这些表述。
还有个进阶技巧:结合翻译工具进行改写。先把 AI 生成的中文内容翻译成英文,再翻译回中文。这个过程会自然引入不同的表达方式,降低重复率。但要注意,翻译后一定要人工校对,避免出现逻辑混乱。
对于长文,建议分段处理。每段先用 AI 生成,然后单独查重、单独修改。这种 “化整为零” 的方法,比写完再改效率高得多,也能更精准地控制重复率。
📌 未来趋势:AI 与查重的 “攻防战”
AI 技术和查重技术的对抗正在升级。一方面,新一代大模型开始加入 “反查重” 训练。比如某些模型会刻意改变标点使用习惯,模仿人类写作中的 “不完美”,让生成内容更难被识别。
另一方面,查重系统也在进化。除了分析文本特征,新的查重技术开始结合语义分析 —— 即使你改写了句子,只要核心意思和已有内容高度相似,也能被检测出来。
这意味着,未来单纯依靠技术手段降低查重率会越来越难。真正的解决方案,可能是找到 AI 和人类协作的平衡点。比如,用 AI 做资料整理和框架搭建,然后由人类注入独特的观点、经验和表达方式。
教育领域已经开始探索这种模式。有些学校不再完全禁止 AI 使用,而是要求学生在 AI 生成的初稿上进行大幅度修改,并提交 “修改说明”,证明自己对内容有深入理解和创造性加工。


为体育公众号引流?")












