🕵️♂️ 先搞懂查重系统的核心逻辑:它到底在查什么?
很多人以为查重系统就是简单比对文字重复率,这想法太天真了。现在的智能查重系统早就升级了,尤其是针对 AI 生成内容的检测工具,比如 GPTZero、Originality.ai 这些,它们玩的是「特征捕捉」的活儿。
核心逻辑就两条:一是比对文本与现有数据库的相似度,这和传统论文查重思路类似,但数据库量级天差地别 —— 现在的系统能接入全网公开文本、书籍、期刊甚至社交媒体内容,量级达到百亿级。二是识别 AI 生成文本的固有特征,比如特定的句式偏好(喜欢用长句套从句)、逻辑衔接词的高频使用(“因此”“然而” 这类词出现的概率比人类写作高 30% 以上)、语义重复模式(同一概念换种说法却保持相同逻辑结构)。
举个例子,AI 写 “人工智能的发展”,大概率会先定义概念,再讲历史沿革,接着分点说应用领域,最后总结趋势。这种结构化的叙事模式,就像给文本打上了隐形水印,查重系统一眼就能认出来。人类写作反而更随性,可能突然插入一个案例,或者从个人经历切入,这种 “不规整” 恰恰成了原创的证明。
更狠的是,现在的系统还会分析语义向量。简单说,就是把文字转换成数字矩阵,通过算法计算两段文本的语义相似度。哪怕你把 “今天天气很好” 改成 “今日气候宜人”,字面不一样,但语义向量接近,照样会被标记。
🔍 逆向工程拆解:查重系统的 “三板斧”
想让 AI 内容躲过查重,就得先知道系统是怎么 “看” 文本的。逆向分析主流查重工具的检测流程,能发现它们都离不开这三个步骤:
第一步是文本预处理。系统会先去掉标点、停用词(比如 “的”“是” 这类无实际意义的词),把文本拆成最小语义单位 —— 可能是词,也可能是短语。比如 “AI 生成内容容易查重” 会被拆成 “AI”“生成”“内容”“容易”“查重”。这一步的目的是过滤噪音,聚焦核心信息。
第二步是特征提取。这是最关键的一步。系统会提取两类特征:表层特征和深层特征。表层特征包括词频(某个词出现的次数)、句式长度分布(长句和短句的比例)、段落结构(开头结尾的特征词)。深层特征则是语义关联,比如 “人工智能” 和 “机器学习” 的共现概率,“数据” 和 “算法” 的搭配频率 ——AI 生成文本在这些关联上有明显的模式化倾向。
第三步是模型比对。系统会把提取到的特征扔进训练好的分类模型里,这个模型是用海量的人类写作和 AI 写作样本训练出来的。模型会计算待检测文本的 “AI 概率值”,如果超过设定的阈值,就会判定为 AI 生成。同时,还会和数据库里的文本进行相似度比对,双重验证。
有意思的是,不同查重系统的侧重点不一样。Turnitin 更看重学术文本的数据库比对,而 Originality.ai 则更依赖 AI 特征模型。这也是为什么同一段文本在不同平台查重结果可能差很远的原因。
✍️ 避免高查重率的核心思路:打破 “AI 特征茧房”
既然查重系统盯着 AI 的固有特征,那破解之道就是主动破坏这些特征,让文本看起来更像 “人类手写”。这不是简单改几个词的事儿,得从根上调整生成逻辑。
首先要做的是 “词汇替换但语义守恒”。AI 爱用的高频词必须换掉,比如把 “非常重要” 改成 “至关关键”,“很多人” 换成 “多数群体”。但这里有个坑,不能用同义词替换工具批量改,那样很容易出现语义偏差,比如 “他很生气” 改成 “他很愤怒” 没问题,但改成 “他很恼火” 在某些语境下就不对。最好的办法是理解句子意思后,用自己的词汇库重新表达。
其次要打乱句式节奏。AI 写东西总爱用 “因为… 所以…”“虽然… 但是…” 这类逻辑词,而且句子长度相对均匀。人类写作就随意多了,可能一句话只有两三个字,下一句又有十几个字。可以刻意让 AI 生成的内容加入短句、插入语,比如在长句中间加个 “说白了”“你看”,或者突然来一句 “这事儿得这么看”,打破模式化的节奏。
最重要的是注入 “个性化杂质”。人类写东西难免有重复、口误甚至逻辑小跳跃,这些 “不完美” 恰恰是原创的证明。比如在文本里加一句 “我上次遇到类似情况是在…(举个个人经历的小例子)”,或者 “这里可能说得有点绕,简单讲就是…”。这些看似多余的内容,会大幅降低查重系统的 “AI 概率判定”。
🛠️ 实操策略:从生成到修改的全流程优化
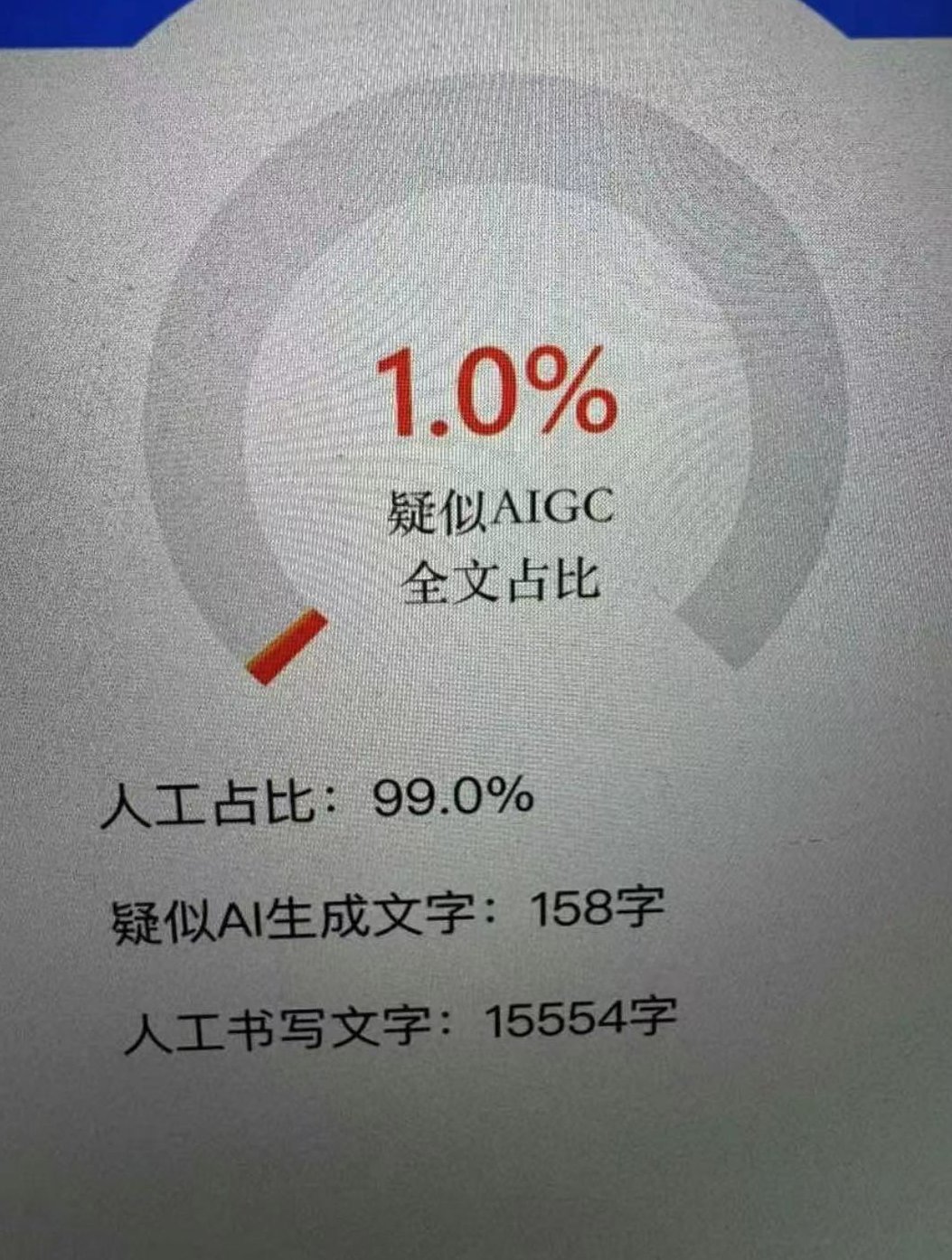
光有思路不够,得有能落地的方法。分享一套经过实测有效的流程,亲测能让 AI 生成内容的查重率降到 10% 以下(以 Originality.ai 为标准)。
生成阶段就要埋下 “反检测” 的种子。给 AI 的提示词里必须加这些要求:“用口语化表达,避免书面语;加入具体的案例或数据(比如 “某公司去年的数据显示…”);适当使用行业黑话或特定领域的小众术语;每段话结尾加一个自然的过渡句,比如 “这还不是最关键的”“接着往下看就明白了”。
举个例子,想让 AI 写 “AI 在教育中的应用”,别直接说 “写一篇关于 AI 在教育中应用的文章”,而是说 “用老师聊天的语气写 AI 在课堂上的用法,多举几个具体的课堂例子,比如批改作业、个性化辅导这些,中间穿插点‘你知道吗’‘说实话’这类话,别用太专业的词,像说大白话一样”。这样生成的初稿就自带 “人类特征”。
修改阶段要做 “三层过滤”。第一层改词汇,把所有 AI 高频词替换成低频词或领域专属词;第二层调结构,打乱段落顺序,把总结性的话挪到中间,把例子提前;第三层加细节,每个观点后面都加一个具体的场景描述,比如提到 “AI 提高效率”,就加一句 “比如我们部门用 AI 做报表,以前要两小时,现在二十分钟就搞定,还少了好几个错误”。
这里有个小技巧,用 “跨领域类比” 增加独特性。比如写科技类文章时,突然用 “这就像做饭,食材再好,火候不对也白搭” 这样的生活化类比,这种跨领域的联想在 AI 生成内容里很少见,查重系统很难匹配到相似文本。
🧠 进阶玩法:利用查重系统的 “盲区”
查重系统不是万能的,它也有识别不到的地方,善用这些 “盲区” 能事半功倍。
语义深度是个大盲区。现在的查重系统能检测到表层文字和简单语义,但对深层逻辑、复杂情感的识别还很弱。比如写一篇分析文章,不光说 “是什么”,还要多写 “为什么会这样”“背后的本质是…”,加入自己的深度解读。这些个性化的思考链条,数据库里很难找到完全匹配的内容。
时效性内容容易钻空子。查重系统的数据库更新有延迟,最新发生的事件、数据、热点话题,数据库里还没有足够的比对样本。比如结合当天的新闻事件写评论,或者引用刚发布的行业报告数据,这样的内容查重率天然就低。但要注意,引用数据必须准确,别为了降重瞎编。
方言和口语化表达的优势。把文本里的部分内容换成方言词汇或口语化表达,比如北方人说 “这事儿不靠谱”,南方人说 “这东西不顶用”,这些带有地域特色的表达,AI 生成时很少用,查重系统也很难识别为重复内容。但别用太多,不然影响阅读体验。
🚨 避坑指南:这些做法只会让查重率更高
很多人踩过的坑,千万别再跳了。这些看似有用的方法,其实是在给查重系统 “送分”。
千万别用 “同义词替换器” 批量修改。这种工具改出来的文本,词汇虽然换了,但句式、逻辑结构完全没变,AI 特征反而更明显。查重系统一眼就能看出是 “人工修改的 AI 文本”,直接判高重复率。
别刻意堆砌生僻词。有人觉得用冷门词能降重,结果把文本写成了 “天书”,比如把 “重要” 写成 “至为关键”,“问题” 写成 “疑难杂症”。这种刻意为之的 “独特性”,反而会被查重系统标记为 “异常特征”,增加怀疑度。
别大段复制粘贴案例。为了降重,有人会从网上找一堆案例塞进文本里,结果这些案例本身就在查重数据库里,反而导致重复率飙升。案例一定要用自己的话重新描述,哪怕是同一个例子,换个角度、加几句自己的解读,效果就完全不同。
说到底,避免高查重率的核心不是 “对抗” 查重系统,而是让 AI 生成的内容无限接近人类的自然表达。毕竟,查重系统的初衷是打击抄袭,而不是为难 “像人一样写作” 的内容。只要你的文本有独特的观点、个性化的表达和真实的思考痕迹,哪怕是 AI 生成的,也能轻松通过查重检测。
【该文章由diwuai.com
第五 ai 创作,第五 AI - 高质量公众号、头条号等自媒体文章创作平台 | 降 AI 味 + AI 检测 + 全网热搜爆文库🔗立即免费注册 开始体验工具箱 - 朱雀 AI 味降低到 0%- 降 AI 去 AI 味】















