📌 从技术根源看:并非严格同源但同属 NLP 大家庭
很多人觉得 AI 降重和机器翻译长得像,就以为它们是一个妈生的。其实不是。它们都属于自然语言处理(NLP)这个大领域,但早期发展路径不太一样。
机器翻译的历史能追溯到上世纪 50 年代,当时冷战背景下,美苏都想快速破解对方的语言信息,催生了早期的规则式机器翻译。那时候还没有 AI 的概念,就是靠语言学家手工编写语法规则和双语词典来实现翻译。
AI 降重是近几年才火起来的,随着互联网内容爆炸,查重需求激增,才从文本改写技术里分化出来。早期的降重工具很简单,就是替换同义词、调整语序,和机器翻译早期的规则式思路有点像,但技术源头并不重合。
不过到了 2010 年后,两者开始走到一起。因为深度学习尤其是 Transformer 模型的出现,让 NLP 领域的很多技术都开始共享底层框架。现在你去看主流的 AI 降重工具和机器翻译系统,不少都基于 BERT、GPT 这些预训练模型开发,这时候才算有了真正意义上的技术交集。
🔍 核心原理对比:一个求 “变” 一个求 “通”
别看两者都在跟文字打交道,干活的思路完全不一样。
AI 降重的核心目标是 “形式变,意思不变”。它拿到一段文本,首先要做的是深度理解语义,然后在词汇、句式、结构上做手脚。比如把 “人工智能技术发展迅速” 改成 “AI 技术正以飞快的速度向前演进”,词语换了,句子结构也调了,但说的还是一回事。它得保证改完之后,查重系统认不出来,但人读着还通顺。
机器翻译则是 “意思通,形式跟着语言走”。它要先把一种语言的语义提取出来,变成一种中间表示,再转换成另一种语言的表达。比如把中文 “我爱中国” 翻译成英文 “I love China”,不仅要保证意思对,还要符合英文的语法习惯,主谓宾的顺序不能乱。这里面最麻烦的是处理文化差异和歧义,比如 “龙” 在中文里是吉祥的象征,在英文里却常带负面含义,翻译时就得特别注意。
简单说,AI 降重是在同一语言内部玩花样,机器翻译是在不同语言之间架桥梁。前者更关注文本的 “独特性”,后者更关注 “准确性” 和 “流畅性”。
🌐 应用场景差异:解决的是两类完全不同的问题
这俩技术的应用场景几乎不重合,一眼就能看出区别。
AI 降重主要活跃在内容创作领域。学生写论文怕查重率太高,会用它改改句子;自媒体作者想快速生产多篇相似主题的文章,也会用它做批量改写;甚至一些企业的文案部门,为了避免和之前的宣传材料重复,也会借助它来调整表达。它解决的是 “内容重复” 的问题,本质上是提高内容的原创性表象。
机器翻译则是跨语言沟通的工具。外贸从业者用它看外文合同,游客用它在国外问路,学者用它查阅外文文献。现在很多软件内置的翻译功能,比如浏览器的网页翻译、手机的实时翻译,背后都是机器翻译技术在支撑。它解决的是 “语言不通” 的问题,让不同语言背景的人能交流。
当然也有例外情况。有些时候,有人会先把中文翻译成英文,再翻译回中文,用这种 “曲线救国” 的方式来降重。这其实是利用了机器翻译的 “不完美”—— 两次翻译后难免会有表达上的偏差,刚好能起到降重的效果。但这种方法出来的文本往往读起来别扭,专业的 AI 降重工具不会这么干。
🤖 底层技术的那些 “暗线联系”
虽然目标不同,但两者在技术上确实有不少共通的 “家底”。
最明显的是预训练模型的共享。现在不管是做 AI 降重还是机器翻译,很少有人会从零开始训练模型。大家都会先用海量的文本数据(比如维基百科、书籍、网页内容)预训练一个大模型,让它先学会基本的语言规律。然后再用专门的数据(降重用的是大量改写前后的平行文本,翻译用的是双语平行语料)进行微调,让模型适应具体任务。像 GPT-4 这样的大模型,既能做翻译,也能做降重,就是因为它的通用语言理解能力足够强。
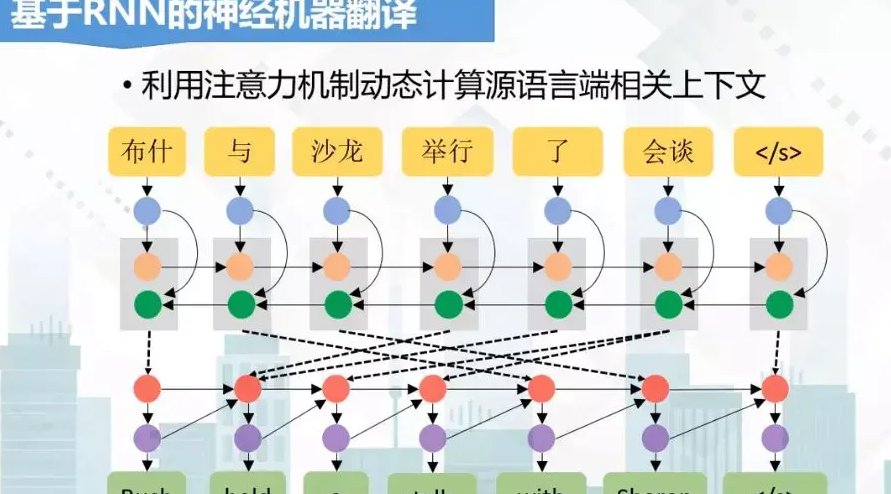
还有注意力机制的应用。这个技术能让模型在处理文本时,重点关注和当前任务相关的部分。在机器翻译里,它能帮模型确定 “中文的哪个词对应英文的哪个词”;在 AI 降重里,它能让模型知道 “哪个词是核心概念不能随便改,哪个词可以替换”。没有注意力机制,这俩技术的效果都会大打折扣。
另外,两者都依赖大规模语料库。机器翻译需要大量双语对照的句子来学习翻译规则,AI 降重则需要大量同义句对来学习改写技巧。这些语料库的质量直接决定了最终效果,所以现在很多公司都在花大价钱收集和清洗数据。
📈 发展路径:各走各的路但偶尔互相 “抄作业”
这两项技术的发展节奏不太一样,但经常互相借鉴对方的成果。
机器翻译起步早,技术成熟度更高。从早期的规则翻译,到统计机器翻译,再到现在的神经机器翻译,每一步突破都给 NLP 领域提供了新的思路。比如神经机器翻译中常用的编码器 - 解码器架构,后来就被用到了 AI 降重工具中,用来实现 “理解原文 - 生成改写文” 的过程。
AI 降重是后起之秀,它的发展更多是搭了预训练模型的便车。但它也有自己的创新,比如 “语义保持度评估” 技术,就是专门用来衡量改写后的文本和原文意思是否一致的。这项技术现在也被用到了机器翻译的质量评估中,用来判断翻译结果是否准确传达了原文的意思。
还有一个很有意思的现象,现在有些机器翻译系统会借鉴 AI 降重的 “同义替换” 思路,来提高翻译的多样性。比如同一个句子,第一次翻译成 “他跑得很快”,第二次可能翻译成 “他跑起来速度很快”,这样用户有更多选择,体验更好。
🚀 未来可能的融合点:1+1 能大于 2 吗?
虽然现在是各干各的,但未来这两项技术很可能会走得更近。
一个可能的方向是跨语言降重。比如一篇英文论文,想翻译成中文后还和其他中文文献不重复,就需要机器翻译和 AI 降重的协同工作:先准确翻译,再进行本地化的降重处理。现在已经有一些学术翻译工具在尝试做这件事,但效果还不太理想。
另一个方向是智能改写 + 翻译的一体化工具。比如你写了一段中文,工具能先帮你改成更通顺的表达(类似 AI 降重的优化),再翻译成英文,并且保证英文版本也符合目标语言的表达习惯。这种工具对跨境内容创作者来说会非常实用。
不过融合也面临挑战。AI 降重追求 “变”,机器翻译追求 “准”,两者的目标存在一定冲突。怎么在保证翻译准确性的同时,又能实现有效的降重,还需要更多技术突破。但可以肯定的是,随着大模型能力的不断提升,这种融合会越来越普遍。
总的来说,AI 降重和机器翻译技术不算严格同源,但在发展过程中逐渐共享了很多底层技术。它们就像 NLP 领域的两个兄弟,长得有点像,会互相学习,但各有各的本事,解决的是不同的问题。未来随着技术的进步,我们可能会看到更多它们联手的场景,给我们的工作和生活带来更多便利。
【该文章由diwuai.com
第五 ai 创作,第五 AI - 高质量公众号、头条号等自媒体文章创作平台 | 降 AI 味 + AI 检测 + 全网热搜爆文库🔗立即免费注册 开始体验工具箱 - 朱雀 AI 味降低到 0%- 降 AI 去 AI 味】















