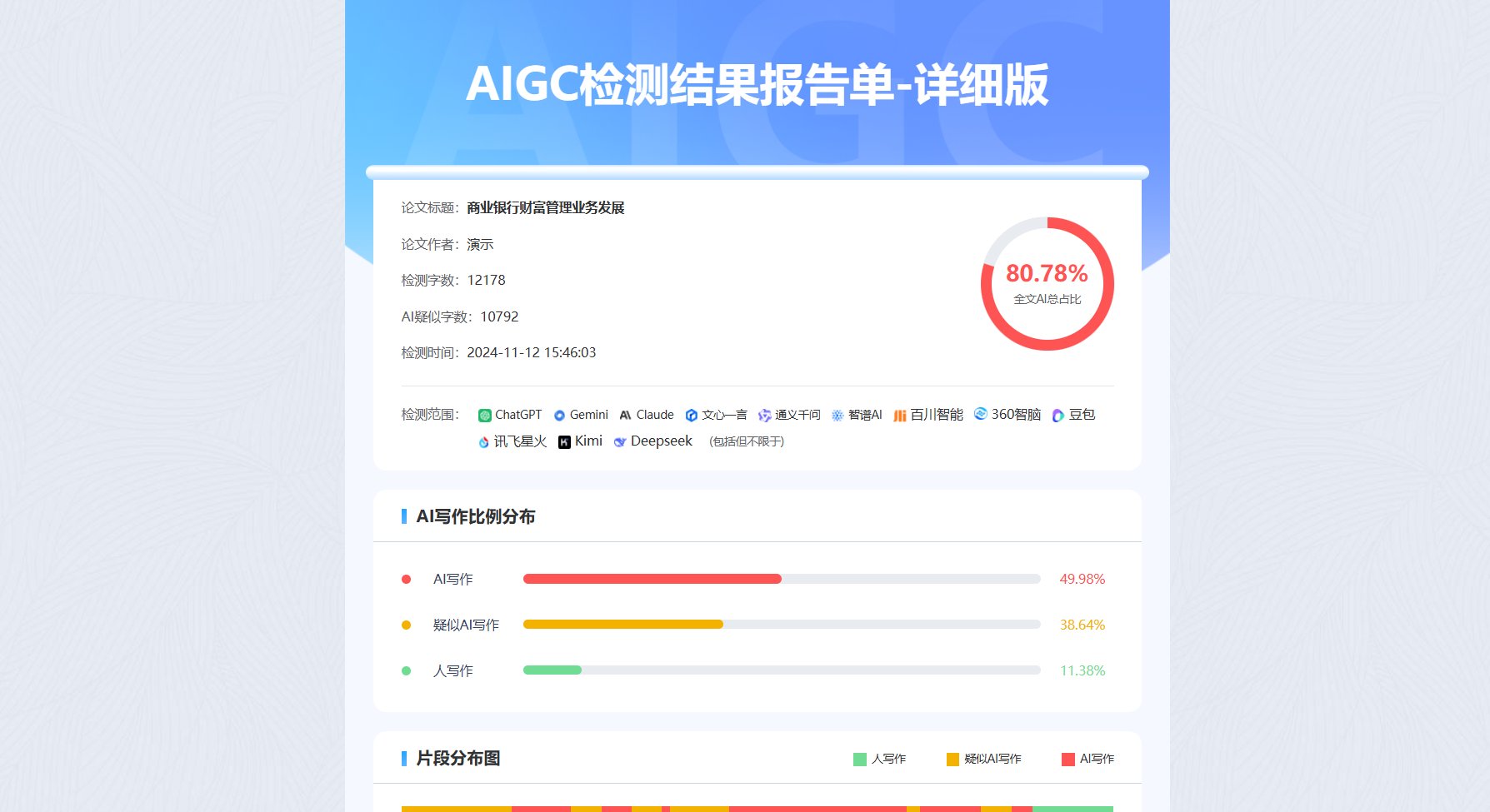
📊 论文 AIGC 检测报告核心指标拆解
拿到检测报告先别急着改,得先看懂这几个关键数据。最显眼的肯定是总体 AI 生成概率,一般分低(<30%)、中(30%-60%)、高(>60%)三个档位,这个数值直接决定了论文是否需要大改。但别只看总体,重点在下面的分段检测结果 —— 有些论文总体达标,却在摘要、结论这类关键段落标红,照样会被打回。
拿到检测报告先别急着改,得先看懂这几个关键数据。最显眼的肯定是总体 AI 生成概率,一般分低(<30%)、中(30%-60%)、高(>60%)三个档位,这个数值直接决定了论文是否需要大改。但别只看总体,重点在下面的分段检测结果 —— 有些论文总体达标,却在摘要、结论这类关键段落标红,照样会被打回。
然后得盯紧句子级 AI 特征标记。好的检测系统会用不同颜色标出可疑句子,黄色可能是用词模式接近 AI,红色则是结构或逻辑明显有机器生成痕迹。比如长句里突然出现过于规整的排比,或者学术术语堆砌却缺乏实际论证,都容易被标红。
还有个容易被忽略的指标是语义一致性评分。AI 生成内容常出现 "前言不搭后语" 的情况,检测系统会通过上下文逻辑关联度来扣分。如果某段话的语义一致性低于 70%,哪怕 AI 概率不高,也可能被判定为 AI 辅助过度。
最后看文献引用匹配度。很多人用 AI 生成时会让模型虚构参考文献,检测系统会比对全网数据库,标红那些不存在或不相关的引用。这部分一旦出现问题,不仅是 AI 检测的事,还可能涉及学术诚信。
🔍 高风险区域的精准定位技巧
段落级标红的部分要重点排查。通常来说,方法论和实验数据分析部分最容易被判高风险,因为 AI 生成时容易编造不存在的实验步骤或数据逻辑。见过不少论文,明明是自己做的实验,就因为描述太 "模板化",被系统误判成 AI 生成。
段落级标红的部分要重点排查。通常来说,方法论和实验数据分析部分最容易被判高风险,因为 AI 生成时容易编造不存在的实验步骤或数据逻辑。见过不少论文,明明是自己做的实验,就因为描述太 "模板化",被系统误判成 AI 生成。
公式和图表周边文字要特别注意。很多人习惯让 AI 生成公式解释或图表说明,这些文字往往带有明显的机器特征 —— 比如反复使用 "如图所示"、"由表可知" 这类衔接词,或者对数据的解读过于笼统。检测系统对这类套话特别敏感。
摘要和结论是重灾区。这两个部分是论文的门面,也是检测系统重点扫描区域。AI 生成的摘要常出现 "本文研究了..."、"通过分析得出..." 这类标准化表述,建议拿自己的实验记录对照着改,加入具体数据和独特发现会更保险。
参考文献列表别放过。有些检测系统会核对文献格式的统一性,AI 生成的参考文献常出现格式混杂的情况,比如有的加 DOI 号有的不加,或者年份标注混乱。手动整理一遍格式,能降低 5%-10% 的 AI 概率。
✏️ 针对性修改的实操策略
句子层面的修改有个笨办法但很有效:把标红句子拆成短句,再用自己的话重新组合。比如 "基于上述分析可以得出结论,该算法在处理大数据时具有显著优势",改成 "分析到这一步能看出来,这个算法处理大数据的时候,优势确实很明显"。口语化改造能有效降低 AI 特征,但要注意保持学术严谨性。
句子层面的修改有个笨办法但很有效:把标红句子拆成短句,再用自己的话重新组合。比如 "基于上述分析可以得出结论,该算法在处理大数据时具有显著优势",改成 "分析到这一步能看出来,这个算法处理大数据的时候,优势确实很明显"。口语化改造能有效降低 AI 特征,但要注意保持学术严谨性。
段落结构调整要遵循 "三明治法则":先亮观点,再摆数据,最后做分析。AI 生成的段落常把观点藏在中间,或者堆数据不分析。把标红段落按这个结构重组,再加入 1-2 个个人研究中的具体案例,能让内容更像人工撰写。
术语使用要 "留痕"。AI 生成内容喜欢用最标准的学术术语,反而显得刻意。可以适当保留一些自己研究领域的 "习惯表达",比如行业内的简称、特定实验设备的俗称,这些小细节能增加人工痕迹。但注意别用错,术语错误反而会减分。
数据描述要 "添油加醋"。AI 写数据时通常干巴巴的,比如 "实验组准确率为 89.7%"。改成 "实验组做了三次重复实验,准确率分别是 88.9%、90.2%、89.9%,平均下来 89.7%,这个结果比对照组高出 12.3 个百分点,而且三次数据波动不大,说明稳定性还不错"。多写过程和细节,机器味自然就淡了。
📈 二次检测前的自查清单
修改完别急着送检,先自己过一遍 "人工痕迹 checklist"。看看有没有出现大量连续的长句,AI 生成内容平均句长比人工写作长 30% 左右。刻意穿插一些短句,比如在复杂论证后加一句 "这个现象值得再深入研究",能打破机器生成的规律性。
修改完别急着送检,先自己过一遍 "人工痕迹 checklist"。看看有没有出现大量连续的长句,AI 生成内容平均句长比人工写作长 30% 左右。刻意穿插一些短句,比如在复杂论证后加一句 "这个现象值得再深入研究",能打破机器生成的规律性。
检查专业词汇的 "重复密度"。AI 容易在一段里反复用同一个术语,比如连续三句都用 "深度学习"。适当替换成近义词,或者用 "该技术"、"这种方法" 指代,能让用词更自然。
参考文献要 "链起来"。每个引用的文献最好在正文中明确提到其具体贡献,比如 "张三(2023)的研究里提到这个问题时,用的是另一种采样方法,我们这里做了调整..."。这种关联分析是 AI 的弱项,也是人工写作的优势。
通读时留意 "逻辑跳跃点"。AI 写东西有时会突然从 A 话题跳到 C 话题,中间少了 B 环节。自己读的时候但凡觉得 "这里怎么突然说到这个",就补上过渡句。人工写作的逻辑往往有更明显的 "蜿蜒感",不像机器那么直来直去。
❌ 二次修改最容易踩的坑
最常见的错误是只改词不改意。把 "优化" 换成 "改进","显著" 换成 "明显",这种同义词替换对检测系统来说几乎没用。真正有效的修改是改变表达逻辑,比如把因果关系改成递进关系,把主动句改成被动句同时调整语序。
最常见的错误是只改词不改意。把 "优化" 换成 "改进","显著" 换成 "明显",这种同义词替换对检测系统来说几乎没用。真正有效的修改是改变表达逻辑,比如把因果关系改成递进关系,把主动句改成被动句同时调整语序。
不敢大删大改。很多人舍不得删掉标红段落,总想着小修小补。其实如果某段 AI 概率超过 70%,直接删掉重写比修改效率高得多。特别是那些描述研究背景的部分,重新结合自己的研究经历来写,比在 AI 生成内容上修修补补效果好太多。
忽略格式细节。检测系统会注意到标点符号的使用习惯,AI 生成内容的标点往往很规范。适当保留一些 "无伤大雅" 的小瑕疵,比如逗号后面多空了一格,反而更像人工写作。但别太刻意,过度反而不自然。
盲目降低 AI 概率。有些人为了让总体概率降到 30% 以下,把本来没问题的段落也改了。其实检测系统更关注关键段落的质量,摘要、结论、创新点这三块达标了,其他部分稍微高一点问题不大。与其把所有段落都改成低概率,不如保证核心内容的原创性。
🔄 二次修改后的验证技巧
改完先自己读三遍,第一遍默读,第二遍出声读,第三遍倒着读段落(从后往前读)。倒读能帮你发现那些看似通顺实则逻辑混乱的句子,这些往往是 AI 生成的残留痕迹。
改完先自己读三遍,第一遍默读,第二遍出声读,第三遍倒着读段落(从后往前读)。倒读能帮你发现那些看似通顺实则逻辑混乱的句子,这些往往是 AI 生成的残留痕迹。
找个非本专业的人看标红修改部分,问他们 "这段话能不能看懂"。AI 生成内容常出现 "专业术语堆砌但逻辑不清" 的问题,非专业人士能看懂,说明修改到位了。
用不同检测系统交叉验证。不同平台的算法不一样,比如某平台侧重语义分析,某平台侧重句式特征。如果在 2-3 个主流系统里都能达标,基本就稳了。别只信一个平台的结果,有时候会有误判。
隔两天再查一次。刚改完的内容可能因为记忆影响,自己觉得很顺,但过两天再看,往往能发现新问题。大脑对刚生成的文字会有 "滤镜效应",冷却一段时间再检查,更容易挑出 AI 痕迹。
最后提醒一句,AIGC 检测本质是倒逼我们更好地表达研究成果。与其想着怎么 "骗过" 系统,不如借这个机会把论文改得更扎实。毕竟好的研究成果,值得用最清晰、最独特的方式呈现出来。
【该文章由diwuai.com第五 ai 创作,第五 AI - 高质量公众号、头条号等自媒体文章创作平台 | 降 AI 味 + AI 检测 + 全网热搜爆文库
🔗立即免费注册 开始体验工具箱 - 朱雀 AI 味降低到 0%- 降 AI 去 AI 味】
🔗立即免费注册 开始体验工具箱 - 朱雀 AI 味降低到 0%- 降 AI 去 AI 味】















