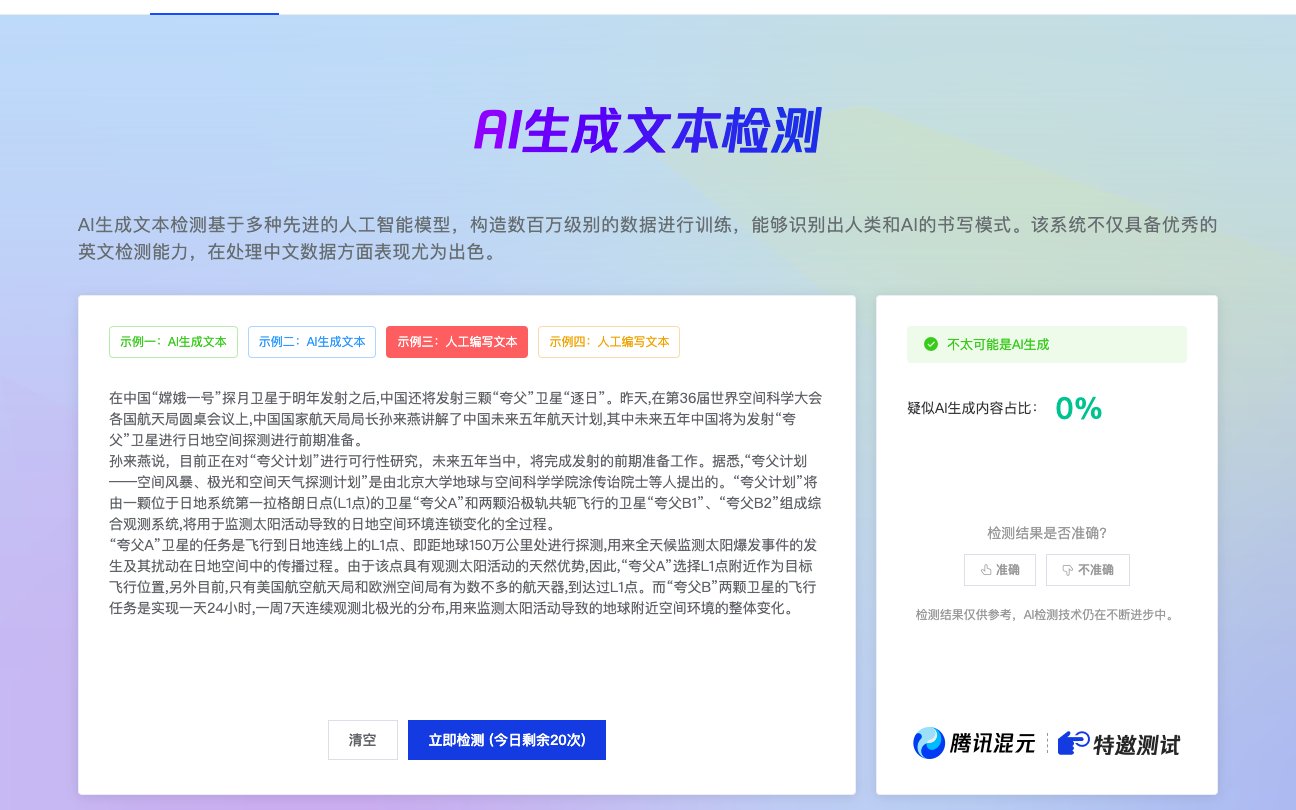
🔍 朱雀 AI 检测 140 万样本训练原理:正负样本如何影响模型性能?
在 AI 生成内容泛滥的当下,腾讯推出的 “朱雀” AI 检测工具成为内容真实性验证的重要防线。这款工具基于 140 万份正负样本训练,在图像和文本检测上分别达到 95% 和 92% 的准确率。但很多人可能好奇,这 140 万样本是如何影响模型性能的?正负样本的选择和比例又在其中扮演了什么角色?
🧩 正负样本:模型训练的基石
在机器学习中,正负样本就像天平的两端,直接影响模型的判断倾向。以图像检测为例,正样本是真实拍摄的照片,负样本则是 AI 生成的图片。朱雀团队收集了人体、人像、风景、地标等多种类型的 140 万样本,覆盖了从摄影到艺术创作的广泛场景。这种多样性让模型能够学习到不同领域的特征差异,比如真实照片的光影过渡更自然,而 AI 生成图像可能出现逻辑不合理的细节,像飞翔的小狗或抽烟的猫咪。
但样本数量并非越多越好。如果负样本中包含大量低质量或重复的数据,反而会干扰模型学习。朱雀团队通过人工筛选和算法过滤,确保负样本集中包含各种典型的 AI 生成特征,比如隐形水印、像素异常等。这种精细化的样本选择,让模型在面对复杂场景时依然能保持高准确率。
⚖️ 样本比例:平衡与倾斜的艺术
正负样本的比例是影响模型性能的关键因素。如果正负样本数量过于悬殊,模型可能会偏向多数类,导致少数类检测效果不佳。在朱雀的训练数据中,正负样本的比例经过精心设计,既保证了模型对 AI 生成内容的敏感性,又避免了对真实内容的误判。
以文本检测为例,AI 生成的文本往往具有低困惑度、用词规律性强等特点。朱雀团队通过调整正负样本的比例,让模型更关注这些特征,从而提高检测的准确性。同时,针对中文文本的特殊性,朱雀还专门优化了语义逻辑分析算法,能够识别出不符合人类语言习惯的表述,比如生硬的句式或重复的用词。
不过,绝对的平衡并不总是最优解。在某些情况下,适当增加负样本的比例可以增强模型的泛化能力。例如,当新的 AI 生成技术出现时,模型能够更快地识别出新型特征,而不会被旧有的样本局限。
🛠️ 技术创新:从数据到算法的突破
为了充分利用这 140 万样本,朱雀团队采用了多项先进技术。在图像检测方面,他们通过捕捉真实图片与 AI 生成图像之间的差异,如纹理、语义和隐形特征,构建了多维度的特征提取模型。这种技术不仅能检测出明显的逻辑错误,还能识别出肉眼难以察觉的细微差异,比如像素级的异常分布。
在文本检测中,朱雀引入了困惑度分析和突发性检测算法。困惑度反映了 AI 模型对文本的预测难度,AI 生成的文本通常困惑度较低;突发性检测则通过分析文本中的模式变化,识别出 AI 生成内容常见的规律性。这两种算法的结合,让朱雀在中文检测上的准确率超过了 92%,显著优于国外同类工具。
此外,朱雀还采用了持续更新的策略。随着 AI 技术的不断进步,新的生成模型和特征不断涌现。朱雀团队定期收集最新的 AI 生成内容,更新训练数据和算法,确保模型始终保持领先的检测能力。
🚀 性能提升:从实验室到应用的跨越
经过 140 万样本的训练,朱雀在实际应用中表现出色。在教育领域,教师使用朱雀检测学生作业中的 AI 生成内容,准确率达到 93%;在新闻媒体行业,编辑们用它验证稿件图片的真实性,有效避免了虚假信息的传播。这些案例证明,科学的样本选择和先进的算法设计,能够让模型在复杂场景中保持高可靠性。
不过,朱雀也面临着新的挑战。随着 AI 生成技术的不断进化,生成内容的真实性越来越高,检测难度也在增加。例如,某些 AI 模型能够生成几乎无法辨别的真实感图片,这对朱雀的特征提取算法提出了更高的要求。为了应对这一挑战,朱雀团队正在研究更复杂的多模态分析技术,结合图像、文本和上下文信息进行综合判断。
🌟 总结:正负样本如何塑造模型灵魂
正负样本是模型训练的起点,它们的选择和比例直接决定了模型的性能和倾向。朱雀通过 140 万样本的精心筛选和先进算法的结合,打造了一款高效可靠的 AI 检测工具。从样本多样性到算法创新,从比例平衡到持续更新,每一个环节都体现了机器学习的科学性和艺术性。
在 AI 技术飞速发展的今天,朱雀的实践为我们提供了一个宝贵的范例:只有深入理解数据的本质,合理运用技术手段,才能让模型在复杂的现实场景中发挥最大价值。无论是教育、媒体还是其他领域,朱雀的成功都证明,通过科学的样本训练和算法优化,我们完全可以在 AI 生成内容的浪潮中守住真实性的防线。
该文章由diwuai.com第五 ai 创作,第五 AI - 高质量公众号、头条号等自媒体文章创作平台 | 降 AI 味 + AI 检测 + 全网热搜爆文库
🔗立即免费注册 开始体验工具箱 - 朱雀 AI 味降低到 0%- 降 AI 去 AI 味
🔗立即免费注册 开始体验工具箱 - 朱雀 AI 味降低到 0%- 降 AI 去 AI 味















