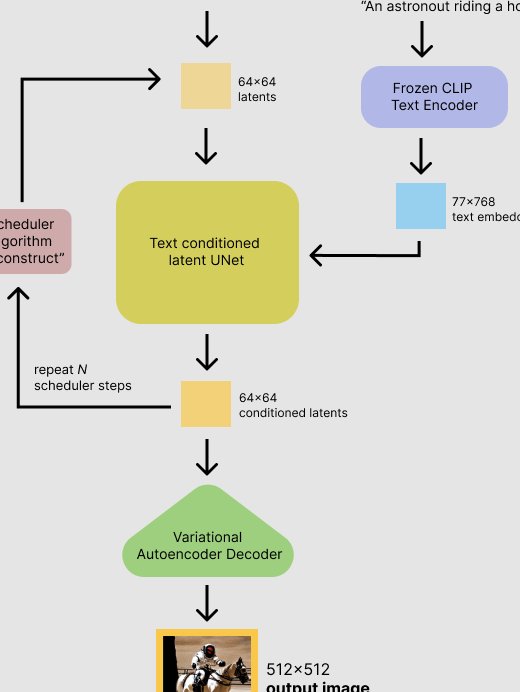
扩散模型(Diffusion Model)如今已经成了 AI 绘画的 “幕后大佬”。从 MidJourney 的超写实人像到 Stable Diffusion 的创意插画,背后都有它的身影。但这个能让文字变成图像的 “黑科技”,到底是怎么运作的?今天就用大白话给你扒透它的底层逻辑。
🧩 扩散模型的基本原理:从 “噪声” 里捞出图像
扩散模型的核心逻辑,其实是模拟了一个 “破坏再修复” 的过程。前向扩散阶段,算法会像给图片蒙上一层层毛玻璃,每次都加入一点点随机噪声,直到原始图像完全变成一团杂乱无章的像素 —— 就像把一张清晰的照片逐渐揉成模糊的纸团。这个过程会持续几十甚至上百步,每一步的噪声参数都被模型默默 “记在心里”。
到了反向扩散阶段,真正的 “魔法” 才开始上演。模型要从那团纯噪声里,一步步 “擦掉” 多余的像素干扰。它会根据前向扩散时记录的噪声信息,反推每一步该去掉哪些噪声,就像考古学家从一堆碎片里拼出完整的陶罐。每一步修复后,图像都会比上一步更清晰一点,直到最后呈现出符合文本描述的画面。
你可能会好奇,模型怎么知道该去掉哪些噪声?秘密藏在训练数据里。工程师会给模型喂入 millions 级的图片 - 文本对,比如 “一只坐在月球上的兔子” 配上对应的插画。模型在学习中会总结出 “兔子有长耳朵”“月球表面坑坑洼洼” 这些视觉规律,反向扩散时就会用这些规律当 “参考手册”,确保修复出来的图像符合人类的认知逻辑。
🆚 扩散模型凭什么打败其他生成模型?
提到 AI 画图,很多人会先想到 GAN(生成对抗网络)。但扩散模型和 GAN 的 “脾气” 完全不同。GAN 就像两个互不相让的艺术家 —— 生成器拼命画 “假画”,判别器则死磕 “辨真假”,两者在对抗中互相进步。但这种机制很容易让模型 “走火入魔”:有时候生成器会陷入 “抄袭” 怪圈,翻来覆去就那几种画风;有时候又会画出五官扭曲的 “惊悚图”,因为判别器一旦被绕晕,生成器就会放飞自我。
扩散模型则走了条更稳健的路。它不需要 “互相对抗”,而是像耐心的工匠一样,一步一个脚印地优化图像。这使得它生成的内容多样性远超 GAN—— 同样是画 “一只戴帽子的猫”,扩散模型能给出从卡通到写实、从波斯猫到橘猫的几十种方案,而 GAN 往往只能在有限风格里打转。更重要的是,扩散模型几乎不会出现 GAN 那种 “崩坏画面”,因为每一步修复都有明确的噪声参数作为参考,就像有导航仪指引着方向。
和 VAE(变分自编码器)比,扩散模型的 “细节把控力” 更胜一筹。VAE 生成的图像往往带着一种朦胧感,就像隔着雾看东西,这是因为它在压缩图像信息时会丢失一些细节。而扩散模型通过数百步的迭代修复,能精准还原发丝的飘动、布料的褶皱,甚至金属表面的反光 —— 这也是为什么现在主流的 AI 绘画工具,几乎都清一色采用了扩散模型架构。
⚙️ 技术难点:为什么画张图要等半天?
虽然扩散模型画出来的图质量高,但它有个让人头疼的毛病 ——慢。一张 512x512 像素的图片,从噪声生成到最终出图,可能需要跑 1000 步迭代。在早期版本的 Stable Diffusion 里,用普通显卡渲染一张图要等好几分钟,这对追求效率的商用场景来说简直是 “致命伤”。
这背后的核心问题,在于每一步反向扩散都要进行复杂的矩阵运算。模型不仅要分析当前图像的噪声分布,还要调用训练时学到的 “图像先验知识”,相当于每一步都在解一道复杂的数学题。而且为了保证精度,这些计算还没法随便简化 —— 就像解方程式时跳过中间步骤,很可能得到完全错误的答案。
另一个难点是文本与图像的对齐。比如用户输入 “一只穿西装的狗,背景是月球”,模型需要准确理解 “西装” 是人类服饰、“月球” 有环形山特征,还要把这些元素合理地组合在狗身上。早期的扩散模型经常闹笑话:要么把西装画成披风,要么让月球看起来像芝士蛋糕。直到 CLIP 模型出现,通过 “文本嵌入 - 图像嵌入” 的双向映射,才总算解决了这个问题 —— 简单说,就是先给模型建立一个 “语言字典”,让它知道 “西装” 对应的视觉特征是什么。
🚀 优化方向:从 “能画” 到 “画得快”
为了解决速度问题,工程师们想出了各种 “偷懒” 的办法。步骤剪枝是最直接的方案 —— 既然 1000 步太慢,那就试试能不能用 50 步达到类似效果?通过优化噪声预测算法,现在的 Stable Diffusion XL 只需要 20-30 步就能生成一张合格的图片,速度比初代版本提升了 10 倍以上。代价当然是细节略有损失,但对大多数场景来说,这种 “牺牲” 是值得的。
模型蒸馏则是另一种思路。简单说,就是先训练一个 “老师模型”(比如 1000 步的完整模型),再让一个 “学生模型” 学习老师的输出结果,最后让学生用更少的步骤达到接近老师的效果。就像老师把复杂的解题思路总结成公式,学生直接套用公式就能快速得到答案。现在 MidJourney 的 “fast mode”,用的就是这种技术 —— 虽然生成的图在细微处不如 “relax mode” 精致,但速度提升了 3 倍以上。
还有个黑科技叫对抗性去噪。它借鉴了 GAN 的对抗思想,在反向扩散时加入一个 “质量判别器”,一旦模型生成的图像足够清晰,就立刻终止迭代。比如画一张简单的风景照,可能 50 步就已经很清楚了,没必要硬撑到 100 步。这种 “见好就收” 的策略,在不损失质量的前提下,能节省 30%-50% 的计算时间。
🌍 主流应用:不止是画画那么简单
现在的扩散模型,早已跳出了 “生成图片” 的单一功能,开始渗透到各行各业。图像修复就是个典型场景 —— 老照片上的划痕、褪色,用扩散模型跑一遍,就能自动填补缺失的像素,让照片恢复原貌。和传统的 PS 修复不同,它不是简单的 “复制粘贴”,而是会根据照片的整体风格,“脑补” 出合理的细节。比如修复一张破损的古建筑照片,模型会参考同类建筑的结构特征,自动补全缺失的飞檐或雕花。
风格迁移也被玩出了新花样。用户只需要上传一张自拍,再输入 “梵高风格”“赛博朋克风格”,扩散模型就能在保留人物特征的同时,把画面转换成对应艺术风格。这比早期的 StyleGAN 更灵活 —— 不仅能换色调和笔触,还能根据风格调整构图,比如把普通人像变成梵高笔下那种旋转扭曲的星空背景。
在3D 生成领域,扩散模型也开始崭露头角。最近爆火的 DreamFusion,就是用扩散模型从 2D 图像反推 3D 模型。用户输入 “一个红色的茶壶”,模型会先生成多个角度的茶壶图片,再通过扩散算法计算出三维空间中的结构关系,最终输出一个可用于 3D 打印的模型文件。这让原本需要专业建模软件花几天完成的工作,现在几小时就能搞定。
🔮 未来趋势:扩散模型会进化成什么样?
速度问题一旦彻底解决,扩散模型的应用场景会爆发式增长。业内已经有团队在尝试用GPU 集群 + 模型并行的方式,把生成速度压缩到秒级 —— 以后在直播里实时生成虚拟背景、在游戏里根据玩家输入即时生成道具,可能会成为常态。想象一下,玩 RPG 游戏时,你随口说 “想要一把水晶做的剑”,游戏引擎调用扩散模型,几秒钟后一把独一无二的水晶剑就出现在背包里,这种体验想想都让人兴奋。
多模态融合会是另一个大方向。现在的扩散模型主要处理图像,但未来很可能会整合声音、文字、3D 模型。比如输入一段音乐,模型能生成匹配旋律情绪的动态图像;或者用文字描述一个 “会唱歌的机器人”,模型不仅能画出机器人的样子,还能生成它的声音特征。这种 “全能型” 模型,可能会彻底改变内容创作的方式。
最后,模型轻量化也是必然趋势。现在想跑 Stable Diffusion,至少需要 8G 显存的显卡,普通用户根本玩不起。但随着压缩算法的进步,未来可能会出现手机端就能流畅运行的扩散模型 —— 就像当年的 AI 美颜算法,从需要服务器支持,到现在能实时跑在手机上。到那时候,每个人都能随时随地用 AI 生成自己想要的图像,创作门槛会被彻底拉平。
说到底,扩散模型的本质,是用数学的方式模拟了人类 “从混沌中寻找秩序” 的认知过程。它之所以能画出让人惊叹的作品,不是因为它 “懂艺术”,而是因为它从海量数据中学会了 “世界的规律”—— 哪些像素组合起来像人脸,哪些线条搭配起来是风景。这种 “用数据理解世界” 的思路,或许不仅能用来画画,还能帮我们解决更复杂的问题。
【该文章由diwuai.com
第五 ai 创作,第五 AI - 高质量公众号、头条号等自媒体文章创作平台 | 降 AI 味 + AI 检测 + 全网热搜爆文库🔗立即免费注册 开始体验工具箱 - 朱雀 AI 味降低到 0%- 降 AI 去 AI 味】



让内容风险无所遁形")











