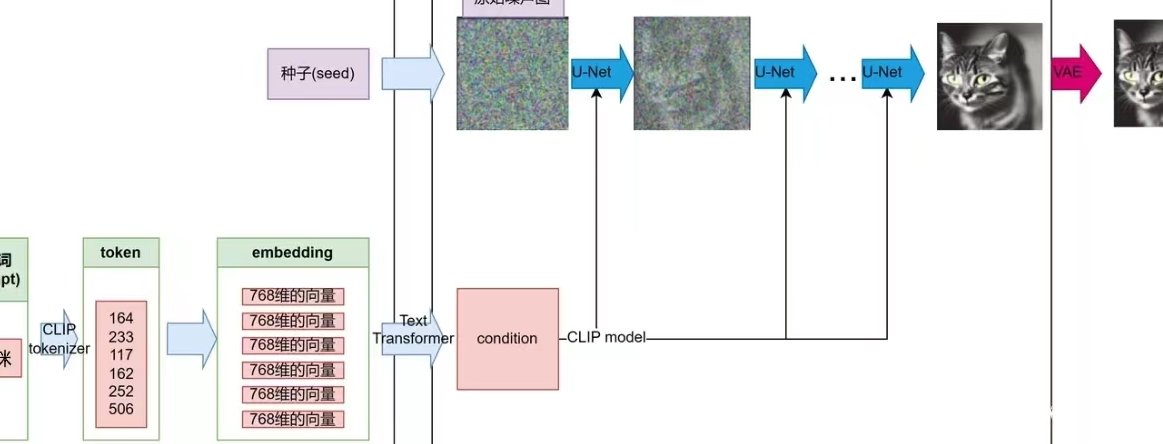
文生图技术这两年火得一塌糊涂,从刚开始只能生成模糊的简笔画,到现在能精准还原复杂场景、抽象概念,甚至连带有隐喻的描述都能拿捏得有模有样。但你有没有想过,当我们输入一句包含多个元素、抽象情感或者隐喻表达的话时,AI 是怎么 “看懂” 这些复杂语义,最后变成一张符合预期的图片的?这背后的逻辑,可比我们看到的 “输入文字出图片” 要复杂得多。
🧩 处理多元素关联:让 “元素拼图” 拼得严丝合缝
现在随便给文生图模型丢一句 “戴着牛仔帽的机器人在月球上喝咖啡,旁边放着一本翻开的旧书”,它基本都能给你生成一张像样的图。但你知道吗?这句话里藏着 5 个核心元素:机器人、牛仔帽、月球、咖啡、旧书,还包含了 “戴着”“在… 上”“喝”“旁边放着” 这些关系描述。文生图技术要处理这种复杂语义,第一步就是把这些元素和关系拆解开,再重新 “拼” 起来。
模型会先通过自然语言处理模块对文本进行 “拆解”,就像我们读句子时会拆分主谓宾一样。它会识别出每个元素的属性 —— 机器人是主体,牛仔帽是它的配饰,月球是场景,咖啡是动作对象,旧书是附加元素。更重要的是,它得搞懂这些元素之间的空间和逻辑关系:牛仔帽 “戴在” 机器人头上,机器人 “在” 月球这个场景里,“喝” 这个动作指向咖啡,旧书 “放在” 机器人旁边。
这里面,注意力机制起到了决定性作用。模型会给每个元素和关系分配不同的 “关注度”,确保关键信息不被忽略。比如 “戴着牛仔帽” 是机器人的核心属性,权重会更高,不会出现帽子戴到咖啡杯上的离谱情况;“月球” 作为场景,会优先确定整体环境基调,再往里面塞其他元素。
但早期模型经常出岔子,比如把 “猫坐在狗的左边” 生成 “狗坐在猫的左边”,或者元素比例失调,咖啡杯比机器人还大。现在之所以能拼得准,是因为训练数据里包含了海量 “元素 - 关系 - 图像” 的对应案例,模型在学习中慢慢摸清了 “谁该在谁旁边”“哪个该大哪个该小” 的规律。
🧠 解析抽象概念:把 “看不见的感觉” 变成 “看得见的画面”
比处理具体元素更难的,是解析抽象概念。比如输入 “孤独的雨夜”,文生图模型怎么知道该画什么?是空荡荡的街道?还是窗边独自发呆的人?又或者是一盏昏黄的路灯在雨里亮着?
其实,模型对抽象概念的理解完全依赖于训练数据中积累的 “语义 - 视觉” 映射关系。在训练时,它见过无数次 “孤独” 这个词和相关图片的搭配:可能是大面积的留白,可能是冷色调(比如蓝色、灰色),可能是单个主体在空旷环境里,也可能是关闭的门窗、熄灭的灯光。这些视觉特征和 “孤独” 这个词反复绑定,模型就慢慢总结出了规律:当出现 “孤独” 时,优先用冷色调、空旷场景、单个主体来表达。
同样,“热闹的集市” 这种抽象场景,模型会调用训练数据里的 “热闹” 相关特征:密集的人群、鲜艳的色彩、动态的肢体(比如挥手、交谈)、多样的摊位,甚至可能加上模糊的动态效果(比如人群的虚影)来强化 “热闹” 的感觉。
但这里有个问题:不同文化对抽象概念的视觉表达可能不一样。比如 “喜庆”,在中国文化里常和红色、灯笼、烟花绑定;在西方文化里可能更多是金色、圣诞树、礼物。所以现在好的文生图模型都会针对不同文化场景做优化,要么在训练数据里加入足够的文化样本,要么通过微调让模型适应特定文化下的抽象概念表达。
🔄 应对隐喻表达:让 “话里有话” 被准确 “翻译”
隐喻是人类语言的精髓,但对文生图技术来说,简直是噩梦级别的挑战。比如 “时间像河流”,总不能真画一条河上面漂着个时钟吧?那也太生硬了。好的模型会怎么处理?它可能会画一条蜿蜒的河,河水呈现流动的动态,河面上漂浮着落叶(象征时间流逝),远处的河岸慢慢模糊(象征过去的不可追回),甚至在河的尽头加一点光晕(象征未来)。
要做到这一点,模型得先搞懂隐喻的 “本体” 和 “喻体”。“时间” 是本体,“河流” 是喻体,核心是两者共有的 “流动性”“不可逆性”。所以模型的重点不是画时间,也不是画河流,而是画 “流动性” 和 “不可逆性” 的视觉表现。
这背后的逻辑,是模型对 “语义相似性” 的捕捉能力。在训练时,它会学习到 “时间” 和 “河流” 在语义上的关联点 —— 都有 “持续向前”“无法回头” 的属性。然后,它会从喻体 “河流” 的视觉特征里,提取出能表达这些属性的元素(比如水流方向、波纹动态),再和本体 “时间” 的相关视觉符号(比如沙漏、日历的虚影)结合,最终生成既符合隐喻又不生硬的画面。
不过,隐喻处理目前还不算完美。如果遇到太生僻的隐喻,比如 “他的笑容像冬日里的破冰船”,模型很可能抓不住重点,要么过分突出 “破冰船” 的机械感,要么完全忽略 “笑容带来的温暖打破冰冷” 这个核心,这也是未来文生图技术需要重点突破的地方。
🔗 处理上下文依赖:让 “前后文” 不冲突、不脱节
我们说话时,经常会用代词、时态、指代来简化表达,但这对文生图模型来说,意味着要处理更复杂的上下文依赖。比如 “小明买了一个红苹果,他把它放在了桌子上。桌子旁边有一把椅子,那是他每天吃饭时坐的。” 这里的 “他” 指小明,“它” 指红苹果,“那” 指椅子,模型必须理清这些指代关系,才能生成逻辑通顺的图片。
解决上下文依赖的关键,是把自然语言处理(NLP)里的 “指代消解” 和 “时态分析” 能力,嫁接到文生图模型里。模型会先像读文章一样,把整个段落拆解成一个个语义单元,标记出每个代词对应的实体:“他”→小明,“它”→红苹果,“那”→椅子。然后分析时态:“买了”“放在了” 都是过去时,但生成图片是静态的,所以模型会通过物品的状态来暗示时态,比如苹果放在桌子上(已经完成 “放” 的动作),椅子的位置和桌子匹配(符合 “每天吃饭时坐” 的日常状态)。
更复杂的是 “动态上下文”,比如 “一开始是晴天,后来乌云来了,最后下起了大雨”。模型需要把三个时间节点的场景融合成一张图,可能会用 “渐变” 的方式:左边是蓝天白云,中间是乌云慢慢覆盖,右边是雨滴和积水,通过空间上的分区来表达时间上的先后。
现在很多文生图工具都支持 “多轮对话生成”,其实就是强化了上下文依赖处理能力。你先让它画 “一间书房”,再补充 “书架上放满科幻小说”,它能记住 “书房” 这个基础场景,只在书架部分做修改,而不是重新画一个完全不相干的场景,这就是上下文依赖处理的实际应用。
🚀 提升复杂语义理解能力的三大趋势
文生图技术处理复杂语义的能力还在快速进化,从目前的发展来看,有三个趋势特别值得关注。
第一个是大语言模型(LLM)和文生图模型的深度融合。以前,文生图模型的语义解析能力是自带的,比较简单;现在很多团队都在把 LLM(比如 GPT-4、LLaMA)当作 “语义解析器”,先让 LLM 把复杂文本拆解得更细,再把解析结果传给文生图模型。比如输入 “一个穿着汉服的女孩在樱花树下弹古筝,背景是远山和夕阳,要有点古风又带点忧伤”,LLM 会先拆解出:主体(女孩)、服饰(汉服)、动作(弹古筝)、场景(樱花树下、远山、夕阳)、风格(古风)、情感(忧伤),甚至会补充细节(比如樱花可以飘几片下来强化忧伤感,夕阳用暖黄色但亮度调低),这样文生图模型拿到的指令更精准,生成的图片自然更贴合需求。
第二个是多模态训练数据的扩容。以前训练文生图模型,主要用 “文本 - 图片” 配对数据;现在越来越多的团队开始加入 “文本 - 图片 - 视频 - 音频” 的多模态数据。比如 “欢快的音乐” 不仅有对应的文本和图片(比如跳舞的人),还加入了欢快的音频波形数据,模型通过跨模态学习,能更精准地理解 “欢快” 这种语义在视觉上该怎么表现 —— 可能是更跳跃的色彩、更动态的姿态、更密集的元素。
第三个是用户反馈的实时优化。现在很多文生图工具都有 “修改” 功能,你说 “这里的猫应该再胖一点”,模型会调整;你说 “天空的蓝色太浅了”,它会加深。这些用户反馈会被收集起来,用来微调模型,让它慢慢理解人类对 “复杂语义” 的具体偏好。比如很多人觉得 “宁静的湖面” 应该有 “倒影”,模型接收多了这类反馈,下次生成时就会主动加上倒影,不用再额外提醒。
📌 最后想说:技术再强,也离不开 “人类的引导”
文生图技术处理复杂语义的能力确实越来越强,但它始终是 “学来的”,不是 “理解的”。它不知道 “孤独” 到底是什么感觉,也不懂 “时间像河流” 的深层哲学,只是靠着海量数据和算法,在 “语义” 和 “视觉” 之间搭了一座桥。
所以,如果你想用好文生图工具,关键是学会 “精准描述”。比如不要只说 “画个好看的场景”,而要说 “画一片有芦苇的湖边,傍晚,有两只白鹭站在水里,远处有艘小船,天空是粉紫色的晚霞,要安静一点”;遇到抽象概念,尽量补充具体视觉线索,比如 “表达思念,就画一个人站在站台,望着火车开走的方向,手里捏着一张车票”。
随着技术发展,未来的文生图模型可能会像人类一样 “懂” 文字背后的情感和逻辑,但至少现在,它还需要我们多一点耐心,多一点引导。毕竟,让机器理解人类的 “言外之意”,本就是件逆天的事,能做到现在这个程度,已经很不容易了。
【该文章由diwuai.com第五 ai 创作,第五 AI - 高质量公众号、头条号等自媒体文章创作平台 | 降 AI 味 + AI 检测 + 全网热搜爆文库
🔗立即免费注册 开始体验工具箱 - 朱雀 AI 味降低到 0%- 降 AI 去 AI 味】
🔗立即免费注册 开始体验工具箱 - 朱雀 AI 味降低到 0%- 降 AI 去 AI 味】















